Python OpenCV Project – Iris Flowers Classification
We offer you a brighter future with FREE online courses - Start Now!!
The Iris flower dataset is widely used in machine learning to develop models that can classify different types of Iris flowers based on their measurements. This OpenCV Iris Flowers Classification project allows us to learn about classification algorithms, feature extraction, and model evaluation.
By working on this Iris Flowers Classification project, we gain practical experience in solving classification problems and can apply this knowledge to other tasks. The Iris flower dataset is also used to compare different algorithms and techniques.
What is KNeighborsClassifier
The KNeighborsClassifier is a straightforward and powerful classification algorithm. It looks at the nearest neighbours of a data point and predicts its class based on the majority of those neighbours. It doesn’t build a complex model but rather remembers the training data, making it efficient for medium-sized datasets. Choosing the right value for k is important because it influences how the algorithm handles outliers and local patterns. Overall, KNeighborsClassifier is a versatile and easy-to-use algorithm widely used for classification tasks.
How to select the K-value?
Choosing the appropriate k-value in KNeighborsClassifier is essential for accurate classification. A common starting point is to use the square root of the training data size. Cross-validation helps assess different k-values and select the best one. Grid search involves testing multiple k-values to find the most accurate option. Considering domain knowledge can also guide k-value selection.
Additionally, the elbow method can be used to find the k-value where the improvement in accuracy starts to plateau. Experimentation and comparison of results are crucial in determining the optimal k-value for your specific classification task.
Iris Dataset
The Iris flower dataset, introduced by Ronald Fisher, contains measurements of 150 Iris flowers belonging to three species. It includes four features: sepal length, sepal width, petal length, and petal width. The balanced dataset is widely used for classification tasks, serving as a benchmark for evaluating algorithms. Its simplicity and small size make it ideal for beginners, and it has been extensively used for teaching, research, and algorithm development.

Prerequisites for Python OpenCV Iris Flowers Classification
A strong grasp of both the Python programming language and the OpenCV library is essential. Apart from this, you should have the following system requirements.
1. Python 3.7 and above
2. Google Colab or Jupyter Notebook
Download Python OpenCV Iris Flowers Classification Project
Please download the source code of Python OpenCV Iris Flowers Classification Project: Python OpenCV Iris Flowers Classification Project Code.
Let’s Implement It
To Implement it, follow the below steps.
1. Import all the libraries that are required during our implementation.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
import seaborn as sns
2. It reads the CSV file from the path given to it.
data = pd.read_csv("IRIS.csv")
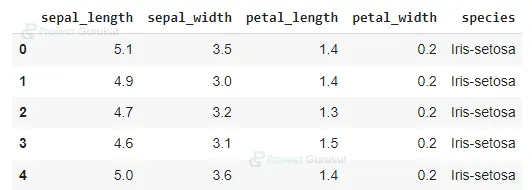
3. It shows the first five rows.
data.head(5)
The output of this step
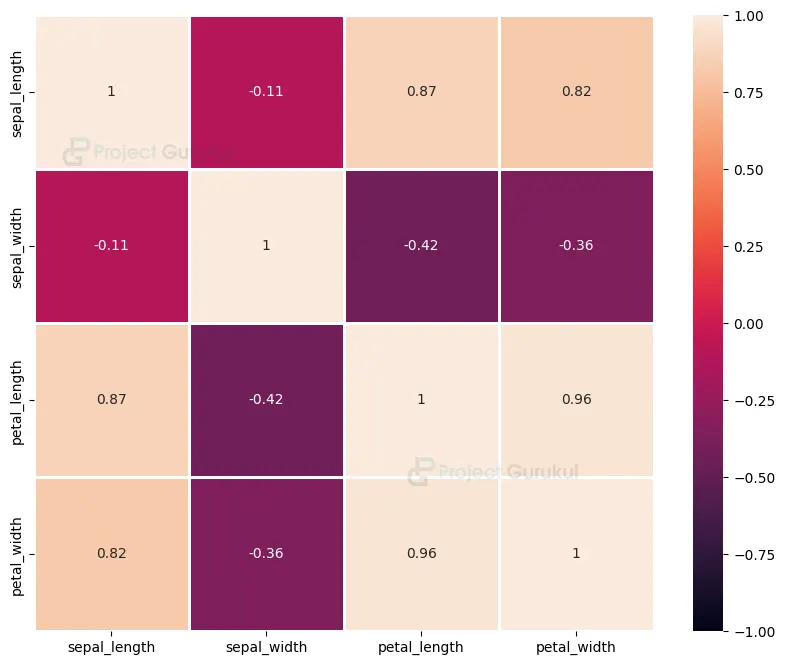
4. It generates a heatmap using Seaborn to visualize the correlation between the features of the Iris flower dataset. The heatmap shows the strength and direction of the relationships between the features. It helps identify patterns and relationships among the features, aiding in feature selection and understanding the data.
plt.figure(figsize=(10,8)) sns.heatmap(data[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']].corr(), vmin=-1.0, vmax=1.0, annot=True, linewidths=2) plt.show()
The output of this step
5. It assigns the features sepal length, sepal width, petal length, and petal width from the Iris flower dataset to the variable x and species to the variable y.
x = data[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']] y = data['species']
6. It splits the dataset into training and testing sets using the train_test_split function. This allows us to train our model on a portion of the data and evaluate its performance on unseen data.
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
7. It creates an instance of the KNeighborsClassifier algorithm with the parameter n_neighbors set to 3.
knn = KNeighborsClassifier(n_neighbors=3)
8. It trains the KNeighborsClassifier model (knn) on the training data (X_train and y_train) using the fit() method.
knn.fit(X_train, y_train)
9. It uses the trained KNeighborsClassifier model (knn) to predict the labels for the test data (X_test) using the predict() method.
y_pred = knn.predict(X_test)
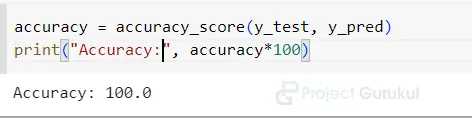
10. It calculates the accuracy of the KNeighborsClassifier model’s predictions by comparing them to the actual labels of the test data.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
The output of this step
11. It predicts the species of a new sample using the trained KNeighborsClassifier model.
new_data = np.array([[5.7, 2.8, 4.1, 1.3]])
prediction = knn.predict(new_data)
print("Predicted species:", prediction)
Output
![]()

Accuracy Of Model
The K-Nearest Neighbors (KNN) classifier performed exceptionally well on the Iris dataset, achieving an impressive accuracy of 100%. This means that the model accurately predicted the species of the iris flowers in the test set with a high level of correctness. A higher accuracy score suggests that the model is reliable and effective in its predictions.
Conclusion
The KNN algorithm applied to the Iris flower dataset successfully classified the flowers based on their features. The model’s accuracy on the test set indicates its ability to generalize to new, unseen data. This OpenCV Iris Flowers Classification project provided valuable insights into classification algorithms, feature selection, and model evaluation. The results can be used to classify future Iris flower samples and serve as a basis for further exploration in classification and pattern recognition.