Machine Learning Project – Keyword Extraction using NLP
FREE Online Courses: Click for Success, Learn for Free - Start Now!
Keyword extraction, a vital task in Natural Language Processing (NLP), involves identifying and extracting keywords or phrases from text, offering a succinct summary of a document’s content. This project employs NLP methods, including text preprocessing, TF-IDF (Term Frequency-Inverse Document Frequency) calculation, and dimensionality reduction, to perform keyword extraction and visualize keyword importance. It encompasses tokenization, lowercase conversion, removal of punctuation and stopwords, TF-IDF score computation, and TruncatedSVD-based keyword identification.
The project concludes with a visual bar chart illustrating TF-IDF scores of extracted keywords. By showcasing how NLP techniques facilitate automated keyword extraction and highlighting significant terms, this project is a valuable tool for efficiently analyzing textual data and gaining insights from it.
About Dataset
No dataset is being used in this Machine Learning Keyword Extraction project.
Tools and libraries used
1. nltk (Natural Language Toolkit): The NLTK library provides essential tools and resources for natural language processing tasks. It includes functions for tokenization (word_tokenize), stopwords removal, and downloading various language resources.
2. string: The string module provides a collection of string constants, such as punctuation characters. It is used here to assist in removing punctuation from text.
3. sklearn (scikit-learn): Scikit-learn is a versatile machine learning library with tools for various tasks, including text processing. In this project, it is used for feature extraction (TF-IDF) and dimensionality reduction (TruncatedSVD).
4. matplotlib.pyplot: Matplotlib is a widely used data visualization library in Python. The pyplot module provides functions to create charts and plots. This project is used to create a bar chart illustrating TF-IDF scores.
5. nltk.corpus.stopwords: The NLTK stopwords corpus contains a list of common stopwords (e.g., “is,” “the,” “and”) in various languages. It is used to remove these stopwords from the text.
6. nltk.tokenize.word_tokenize: The word_tokenize function from NLTK tokenizes input text into individual words or tokens.
7. learn.feature_extraction.text.TfidfVectorizer: The TfidfVectorizer from scikit-learn is used to compute Term Frequency-Inverse Document Frequency (TF-IDF) scores for words in the text. It transforms text data into a numerical matrix suitable for machine learning.
8. sklearn.decomposition.TruncatedSVD: The TruncatedSVD class from scikit-learn performs dimensionality reduction using Singular Value Decomposition. It reduces the number of dimensions while retaining the most essential information.
Download Machine Learning Keyword Extraction Project
Please download the source code of the Machine Learning Keyword Extraction Project: Machine Learning Keyword Extraction Project Code.
Steps to Analyse Machine Learning Keyword Extraction using NLP
1. Importing Libraries: This block of code imports necessary libraries for text processing, feature extraction, dimensionality reduction, and visualization.
import nltk import string from nltk.corpus import stopwords from nltk.tokenize import word_tokenize from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.decomposition import TruncatedSVD import matplotlib.pyplot as plt
2. Downloading NLTK Data: This code downloads the NLTK data required for tokenization (`punkt`) and stopwords (`stopwords`).
nltk.download('punkt')
nltk.download('stopwords')
3. Defining Preprocessing Function: This function takes input text, tokenizes it, converts words to lowercase, removes punctuation, removes stopwords, and joins the words back to form preprocessed text.
def preprocess_text(input_text):
words = word_tokenize(input_text)
words = [word.lower() for word in words]
words = [word for word in words if word.isalnum()]
stop_words = set(stopwords.words('english'))
words = [word for word in words if word not in stop_words]
preprocessed_text = ' '.join(words)
return preprocessed_text
4. Defining Keyword Extraction Function: This function performs keyword extraction using TF-IDF (Term Frequency-Inverse Document Frequency) and TruncatedSVD for dimensionality reduction. It returns the top keywords.
def extract_top_keywords(input_text, num_keywords=5):
preprocessed_text = preprocess_text(input_text)
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform([preprocessed_text])
feature_names = vectorizer.get_feature_names_out()
svd = TruncatedSVD(n_components=num_keywords) # Use TruncatedSVD for dimensionality reduction
tfidf_matrix_reduced = svd.fit_transform(tfidf_matrix)
top_indices = tfidf_matrix_reduced[0].argsort()[::-1]
top_keywords = [feature_names[index] for index in top_indices]
return top_keywords
5. Main Execution: This code block is the primary execution part. It defines the input text, calls the `extract_top_keywords` function to get the top keywords, and prints them.
if __name__ == "__main__":
input_text = """
Natural language processing (NLP) is a subfield of artificial intelligence (AI)
that focuses on the interaction between humans and computers using natural
language. Keyword extraction is an important task in NLP. It involves
identifying the most relevant words or phrases in a text document.
"""
top_keywords = extract_top_keywords(input_text)
print("Top Keywords:", top_keywords)
Output:
6. Visualization: This block of code uses `TfidfVectorizer` to calculate TF-IDF scores for words in the input text, then creates a horizontal bar chart visualization of the TF-IDF scores for the keywords.
# Visualization: Bar chart of TF-IDF scores
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform([preprocess_text(input_text)])
feature_names = vectorizer.get_feature_names_out()
tfidf_scores = tfidf_matrix.toarray()[0]
plt.barh(range(len(feature_names)), tfidf_scores, align='center')
plt.yticks(range(len(feature_names)), feature_names)
plt.xlabel('TF-IDF Score')
plt.ylabel('Keywords')
plt.title('TF-IDF Scores of Keywords')
plt.show()
Output:
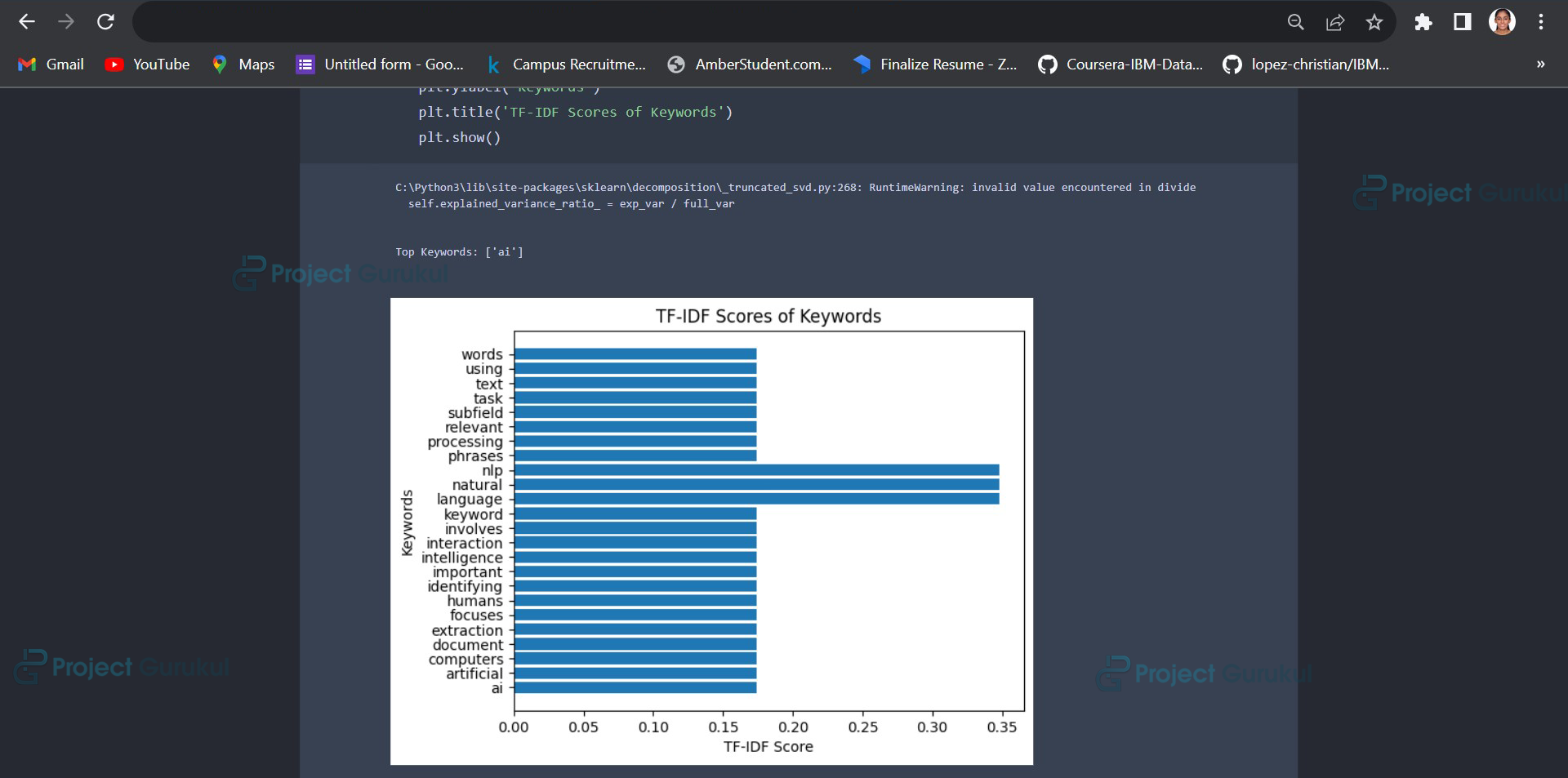
Summary
The Keyword Extraction Project utilizes Natural Language Processing (NLP) techniques to automatically identify and extract the most significant keywords from a text document. The project streamlines the text analysis process by employing various tools and libraries, enabling efficient summarization and understanding of textual content. The key steps involve tokenizing the input text, preprocessing it by converting it to lowercase and eliminating punctuation and stopwords.
The project calculates the Term Frequency-Inverse Document Frequency (TF-IDF) scores, quantifying the importance of words within the document. Utilizing TruncatedSVD for dimensionality reduction, the top keywords are extracted based on their significance. Moreover, the project visually represents keyword importance through a bar chart of TF-IDF scores. Ultimately, this project demonstrates the potential of NLP techniques to enhance information extraction and comprehension, catering to researchers, content creators, and data analysts seeking to gain insights from text data efficiently.
You can check out more such machine learning projects on Project Gurukul.