Create a Language Translator with RNN – Machine Learning Project with Source Code
FREE Online Courses: Your Passport to Excellence - Start Now
What is a Language Translator?
As the name suggests Language translator is that which translates sentences from one language to another. The interesting and main thing here is that we are going to create a language translator using Machine learning. It is very easy to create this using the ‘translate’ library in Python.
This is a very interesting Machine learning project that will enable you to create Language Translator in easy steps. In this project, we will be using Sequence-to-Sequence ( Seq2Seq) Modeling to translate given sentences from one language to another.
So basically the objective of this Language Translator project is that we are going to translate english sentences to french sentences with the help of machine learning.
As we have used “Sequence-to-Sequence (Seq2Seq) Modeling”, so firstly let’s understand this.
About Sequence-to-Sequence (Seq2Seq) Learning:
In Sequence-to-Sequence learning (Seq2Seq) we have to create training models that convert sequences from one domain( e.g. sentences in English) to sequences in another domain (e.g. the same sentences translated to french).
Example:
"you are beautiful" -> [Seq2Seq model] -> "vous êtes belle”
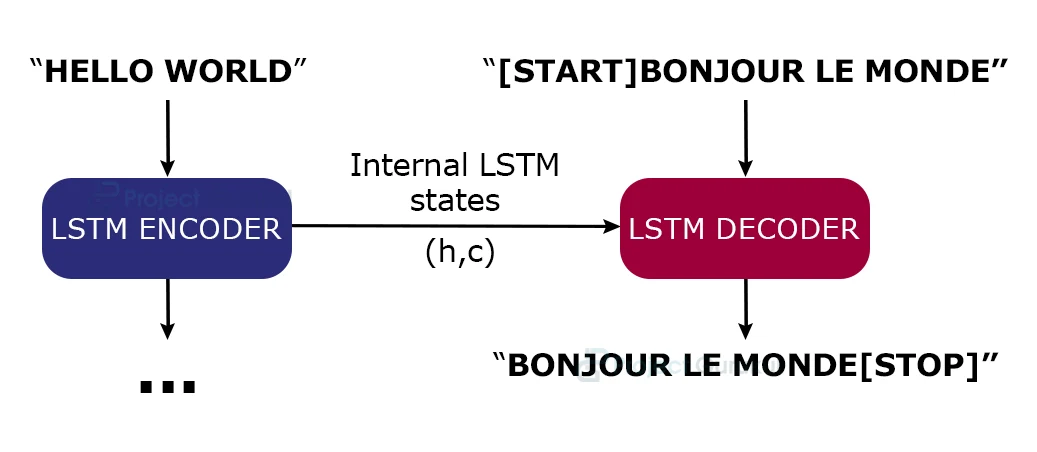
There are various ways to create this project, either using Recurrent neural networks (RNNs) or 1D convnets. But basically we will focus on using RNNs.
There are two cases mainly:
1.) One is, in which we have input and output sequences having the same length.
2.) And the other one is that in which we have different lengths of input and output sequence.
In our case we will be having different lengths of input and output sequence.
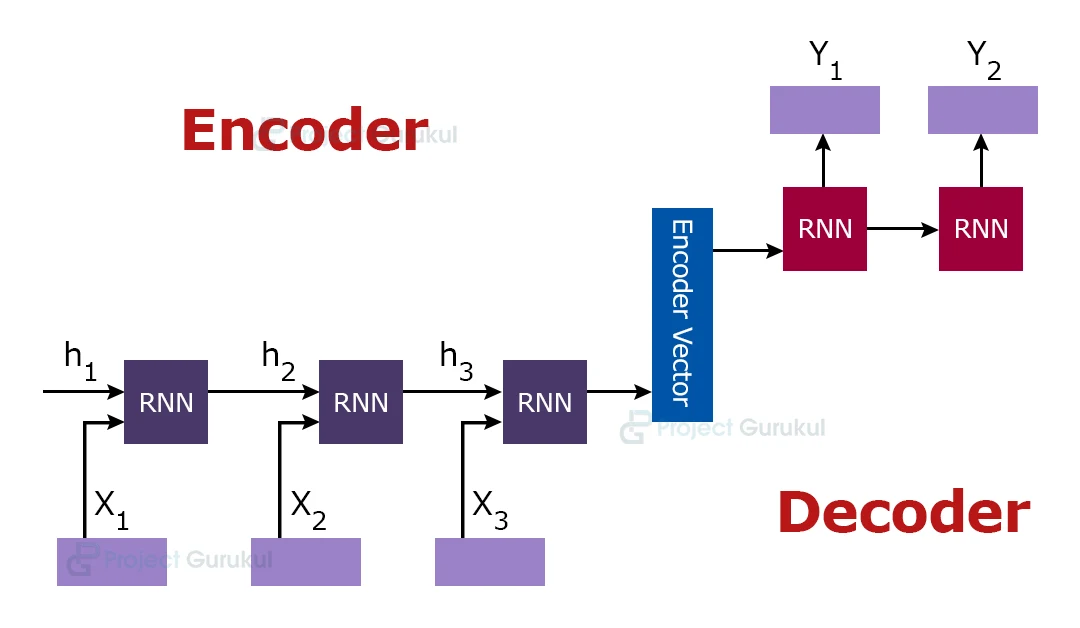
For implementing, we will create two RNN layer :
One RNN layer will act as ‘encoder’: In this we give our english sentence as an input.
And other RNN layer will act as ‘decoder’: which will give us the output (translated sentence in french)
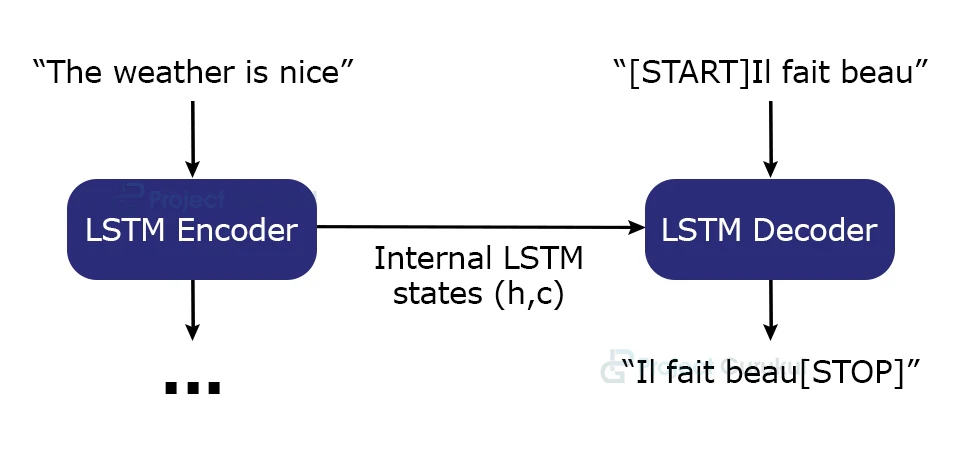
Let’s understand the process that we will be using to implement machine translation:
- Firstly we will encode the input sequence into state vectors.
- Then we will start with a target sequence size 1 (just the start-of-sequence character).
- After this we will feed the state vectors and 1-char target sequence to the decoder to produce predictions for the next character.
- Now sample the next character using these predictions (we simply use argmax).
- Append the sampled character to the target sequence
- And repeat until we generate the end-of-sequence character or we hit the character limit.
Language Translation Dataset
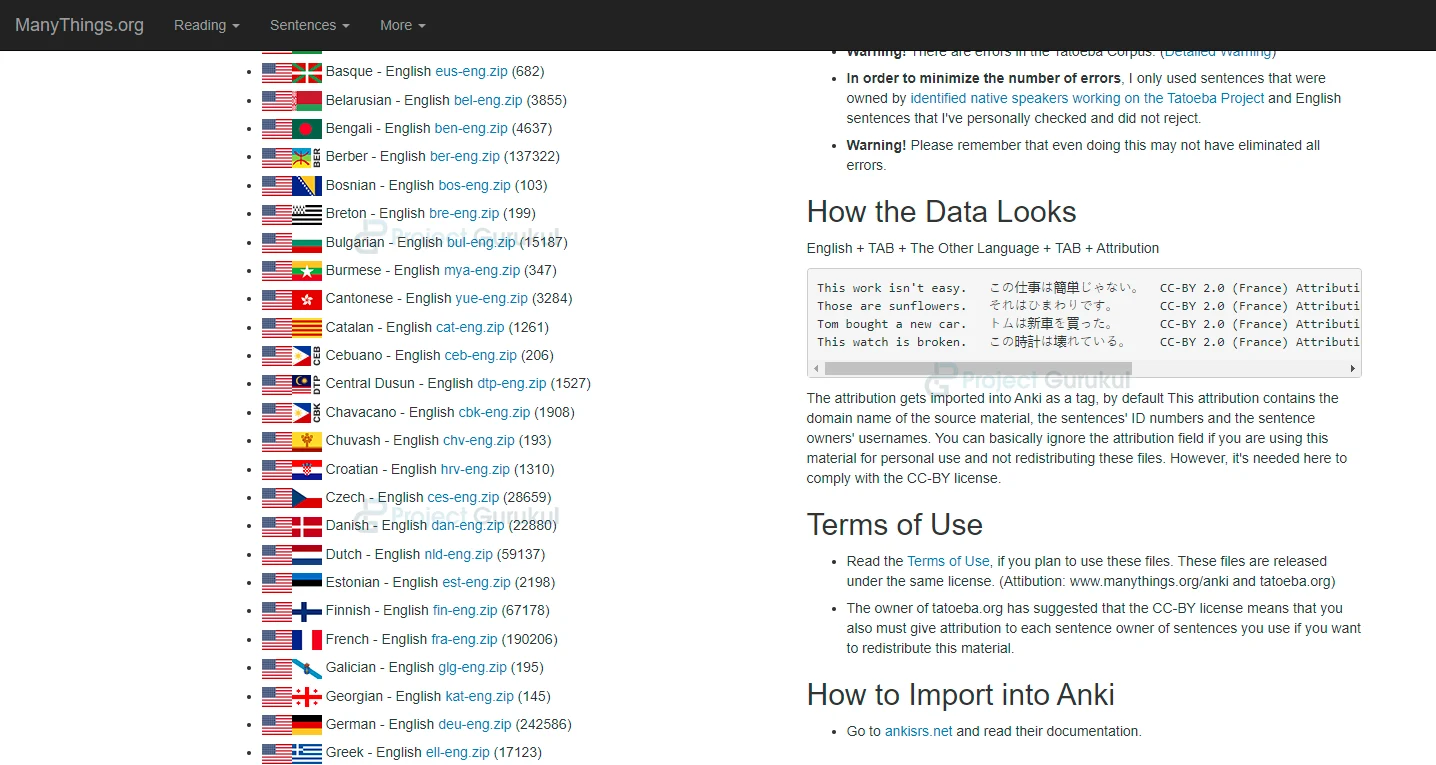
In this machine learning project, we will use a dataset which consists of pairs of English sentences and their French translation, please download the dataset from the following link: language translation dataset
In the link given above there are many datasets, of various different languages, so we have to download french-english dataset as in this ml project we will translate english sentences to french.
So when you open the link you will get something like this, as shown in the image below. In this you have to download fre-eng.zip:
Now after downloading the dataset let’s directly dive into implementation of Machine Translation, and understand how we can create machine translation using machine learning.
Language Translator Machine Learning Project Code
Please download the language translator project code from the following link: Language Translation Project Code
Implementation of Language Translator Project using Machine Learning:
Libraries
You need to have Python installed in your system.
So open your command prompt and install Tensorflow and numpy using:
pip install tensorflow pip install numpy
Now follow steps and understand the implementation:
1. Import libraries:
First we have to import libraries that we will require and use while implementing.
import tensorflow from tensorflow.keras.models import Model from tensorflow.keras.layers import Input, LSTM, Dense import numpy as np
2. Declaring Variables:
Now we will declare some variables like batch size for training (batch_size), Number of epochs to train for (epochs), latent dimensionality of the encoding space (latent_dim), and Number of samples to train on (num_samples)
batch_size = 64 epochs = 100 latent_dim = 256 num_samples = 20000
3. Setting path to dataset:
Set path to the data txt file on disk.
data_path = 'fra.txt'
4. Vectorize the data:
In this step we are reading all the unique characters from input text (i.e english sentence) and also from output text (i.e french sentence). And also separating english sentences to input_texts and french sentences to output_texts as basically our input will be english sentences and output will be french translation of that english sentences, or words.
The input_characters consist of all the unique characters present in input_texts( english sentences) and similarly output_characters consist of all the unique characters present in output_texts (french sentences).
input_texts = []
output_texts = []
input_characters = set()
output_characters = set()
with open(data_path, 'r', encoding = 'utf-8') as f:
lines = f.read().split('\n')
for line in lines[:min(num_samples,len(lines)-1)]:
input_text, output_text, _ = line.split('\t')
# We use 'tab' as the 'start sequence' character
# for the targets, and '\n' as the 'end sequence' character.
output_text = '\t' + output_text + '\n'
input_texts.append(input_text)
output_texts.append(output_text)
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in output_text:
if char not in output_characters:
output_characters.add(char)
5. Assigning Variables:
Now we will assign values to variables, So:
- input_characters consist of a sorted list of all the unique characters present in english text.
- Ouput_character consists of a sorted list of all the characters present in french text.
- num_encoder_tokens and num_decoder_tokens consist of the length of input_characters and output_characters respectively.
- Max_encoder_seq_length and max_decoder_seq_length consist of maximum length of sentence present in the english text and maximum length of sentence in the french text respectively.
input_characters = sorted(list(input_characters)) output_characters = sorted(list(output_characters)) num_encoder_tokens = len(input_characters) num_decoder_tokens = len(output_characters) max_encoder_seq_length = max([len(text) for text in input_texts]) max_decoder_seq_length = max([len(text) for text in output_texts])
6. Assigning tokens:
In this we basically provide a unique index to every character present in input_characters, and output_characters. You can see in the image below.
input_token_index = dict(
[(char,i) for i,char in enumerate(input_characters)])
output_token_index = dict(
[(char,i) for i,char in enumerate(output_characters)])

7. Turn the sentences into 3 numpy arrays:
Basically we will be creating three numpy arrays, that is encoder_input_data, decoder_input_data, and decoder_ouput_data
- encoder_input_data will be a 3D array of shape( num_pairs, max_english_sentence_length, num_english_characters) containing one-hot vectorization of the English sentences.
- decoder_input_data will also be a 3D array of shape( num_pairs, max_french_sentence_length, num_french_characters) containing one-hot vectorization of the French sentences.
- decoder_output_data is same as decoder_input_data but offset by one timestep, decoder_output_data[ : , t , : ] will be same as decoder_input_data[ : , t+1 , : ].
So we will create a 3D array using np.zeros() method in which,
num_pairs = length of input_texts
max_english_sentence_length = max_encoder_seq_length
max_french_sentence_length = max_decoder_seq_length
num_english_characters = num_encoder_tokens
Num_french_characters = num_decoder_tokens
encoder_input_data = np.zeros(
(len(input_texts),max_encoder_seq_length,num_encoder_tokens),dtype = 'float32')
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length , num_decoder_tokens), dtype = 'float32')
decoder_output_data = np.zeros(
(len(input_texts), max_decoder_seq_length,num_decoder_tokens) , dtype = 'float32')
8. One-hot Vectorization:
Let’s first understand the meaning of One-hot Vectorization. In Natural Language Processing one -hot vector is a 1 x N matrix (vector) which is used to distinguish each word in a vocabulary from every other word in the vocabulary.
The vector consists of 0s in all cells with the exception of a single 1 in a cell used uniquely to identify the word.
So in this step we will perform one hot encoding:
for i,(input_text,output_text) in enumerate(zip(input_texts,output_texts)):
for t, char in enumerate(input_text):
encoder_input_data[i,t,input_token_index[char]] = 1.
encoder_input_data[i,t+1:,input_token_index[' ']] = 1.
for t, char in enumerate(output_text):
# decoder_output_data is ahead of decoder_input_data by one timestep
decoder_input_data[i,t,output_token_index[char]] = 1.
if t>0:
# decoder_output_data will be ahead by one timestep
# and will not include the start character
decoder_output_data[i,t-1,output_token_index[char]] = 1.
decoder_input_data[i,t+1:, output_token_index[' ']] = 1.
decoder_output_data[i , t: , output_token_index[' ']] = 1.
You will understand this code, if you understand the above code and concepts.
9. Creating LSTM layer:
Firstly let us understand what LSTM is. The full form of LSTM is Long Short-Term Memory Networks, it is a type of Recurrent Neural Network (RNN). RNN is basically used for sequential data, as it is the first algorithm that remembers its input, due to an internal memory. RNN is used by Apple’s Siri and Google voice search.
LSTM are capable of learning order dependence in sequence prediction problems.This is basically used when you have complex problem domains like speech recognition, machine translation etc.
Now as we have discussed, we will be creating two RNN layers, one will be for encoder and other will be for decoder.
Let’s create LSTM layer for encoder:
# define an input sequence and process it: encoder_inputs = Input(shape = (None, num_encoder_tokens)) encoder = LSTM(latent_dim, return_state= True) encoder_outputs,state_h,state_c = encoder(encoder_inputs) # we discard 'encoder_outputs' and only keep the states. encoder_states = [state_h,state_c]
Now let’s create LSTM layer for decoder:
# set up the decoder, using encoder_states as initial states: decoder_inputs= Input(shape=(None, num_decoder_tokens)) decoder_lstm = LSTM(latent_dim,return_sequences = True, return_state = True) # We set our decoder to return full output sequences, and to return internal states as well but we don’t use this internal states in the training model, # but we will use them in inference. decoder_outputs, _ ,_ = decoder_lstm(decoder_inputs, initial_state=encoder_states) decoder_dense = Dense(num_decoder_tokens,activation = 'softmax') decoder_outputs = decoder_dense(decoder_outputs)
10. Creating a Model:
Now we will create our model in which we will give encoder_inputs, decoder_inputs and decoder_outputs, and also we will compile and fit our model to see accuracy.
# Define the model that will turn
# 'encoder_input_data' & 'decoder_input_data' into 'decoder_output_data'
model = Model([encoder_inputs,decoder_inputs], decoder_outputs)
#Run training:
model.compile(optimizer='rmsprop', loss = 'categorical_crossentropy' , metrics = ['accuracy'])
model.fit([encoder_input_data,decoder_input_data], decoder_output_data,
batch_size=batch_size,
epochs = epochs,
validation_split=0.2)
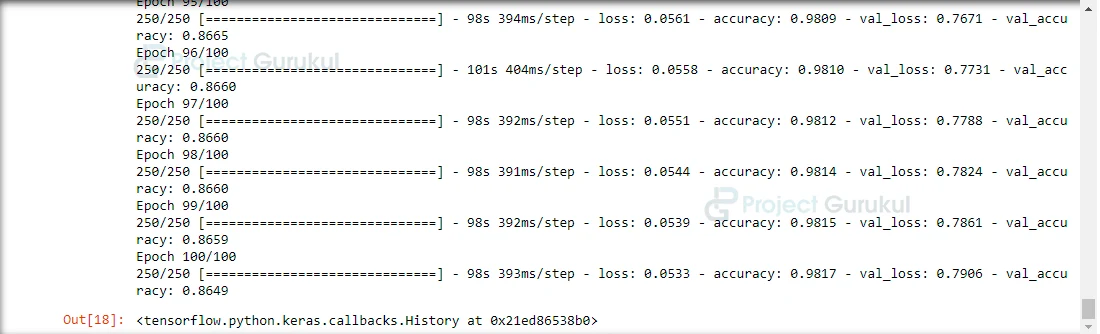
Our model accuracy is 98.2% on our training set, and around 87-88% is validation accuracy which is good.
11. Creating Inference (Sampling):
This is the complete code in which we are able to see our Input sentence and its corresponding decoded sentence. If you completely understand the above code it will be easy for you to understand this code also as in this code we have done similar things as we have done above.
# define sampling models:
encoder_model = Model(encoder_inputs, encoder_states)
decoder_state_input_h = Input(shape = (latent_dim,))
decoder_state_input_c = Input(shape = (latent_dim,))
decoder_input_states = [decoder_state_input_h,decoder_state_input_c]
decoder_outputs,state_h,state_c = decoder_lstm(decoder_inputs, initial_state=decoder_input_states)
decoder_states = [state_h,state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs]+decoder_input_states,
[decoder_outputs] + decoder_states)
# Reverse-lookup token index to decode sequences back to something readable.
reverse_input_char_index = dict(
(i,char) for char,i in input_token_index.items())
reverse_output_char_index = dict(
(i,char) for char,i in output_token_index.items())
def decode_sequence(input_seq):
states_value= encoder_model.predict(input_seq)
output_seq = np.zeros((1,1,num_decoder_tokens))
output_seq[0,0,output_token_index['\t']] = 1
stop_condition = False
decoded_sentences = ''
while not stop_condition:
output_tokens,h,c = decoder_model.predict(
[output_seq]+ states_value)
sampled_token_index = np.argmax(output_tokens[0,-1, :])
sampled_char = reverse_output_char_index[sampled_token_index]
decoded_sentences += sampled_char
if(sampled_char == '\n' or len(decoded_sentences) > max_decoder_seq_length):
stop_condition = True
#update the target sequence (of length 1):
output_seq = np.zeros((1,1,num_decoder_tokens))
output_seq[0,0,sampled_token_index] = 1
states_value = [h,c]
return decoded_sentences
for seq_index in range(20):
# take one sequence for trying out decoding:
input_seq = encoder_input_data[seq_index:seq_index+1]
decoded_sentences = decode_sequence(input_seq)
print('ProjectGurukul Project: English to French Translation ')
print('Input sentence:', input_texts[seq_index])
print('Decoded sentence:' , decoded_sentences)
Language Translator Project Output

Summary
This is very interesting as well as a complex Machine Learning project. In this we have learned many new concepts and also about Recurrent neural networks (RNNs), LSTM layers, how to implement LSTM layers. We’ve also understood the concept behind encoder and decoder and creating RNN models .
And after learning all this we have finally created a Language Translator which translates english text to french.
Thank you for your effort.
I tried to use this code with Arabic dataset from the same source but the output was the same for all inputs. So, please do you know what should I do to fix this problem ?