Hate Speech Detection using Machine Learning
FREE Online Courses: Click for Success, Learn for Free - Start Now!
With this Machine Learning Project, we will be building a hate speech detection system. In this project, we will be using Logistic Regression and TfidfVectorizer as models.
So, let’s build this system.
Hate Speech Detection System
The term “hate speech” refers to any speech that disparages an individual or a group based on one or more characteristics, including race, color, ethnicity, gender, sexual orientation, nationality, religion, or another feature. The volume of hate speech is also steadily rising due to the enormous growth of user-generated web content, particularly on social media networks.
As basic word filters do not adequately address this issue, it is necessary to do natural language processing that particularly targets it. The domain of a statement, its discourse context, as well as context made up of co-occurring media objects (such as images, videos, and audio), the precise time of posting and current global events, the identity of the author, and the identity of the targeted recipient, are the things that can have an impact on what is deemed to be hate speech.
Logistic Regression
Logistic regression is a statistical model which can be used in this project. The algorithm’s output creates a probability value that may be transferred to two or more discrete classes.
This is how the logistic regression model is expressed in formal terms.
log p(x) 1 − p(x) = β0 + x · β
When p is solved, this results
p(x; b, w) = eβ0+x·β 1 + eβ0+x·β = 1 1 + e−(β0+x·β)
You’ll notice that understanding the overall specification in terms of the transformed probability is much simpler than understanding it in terms of the untransformed probability.
We should forecast Y = 1 when p ≥ 0.5 and Y = 0 when p < 0.5. to reduce the misclassification rate. This entails predicting 0 or 1 depending on whether β0 + x ·β is positive or negative. Consequently, logistic regression provides a linear classifier.
The answer to the equation ( β0 + x · β = 0 ) is a decision boundary that separates the two predicted classes. If x is one-dimensional, a point will be the solution; if x is two-dimensional, a line will be the solution, etc. One may demonstrate (do the exercise!) that separate from the choice border. The class probabilities rely on distance from the boundary in a certain way, and they tend to go towards the extremes (0 and 1), according to logistic regression, which also identifies the location of the class. These statements about probabilities make logistic regression more than just a classifier. It makes stronger, more detailed predictions and can be fit differently, but those strong predictions could be wrong.
Regression analysis that is utilized when the dependent variable is binary is called logistic regression. As with SVC and MNB, we trained LR in the same manner. Utilizing L2 regularisation, the hyper-parameter C was left at its default value of 1.0. Using TF-IDF weights, combined word and character n-gram features provide greater accuracy for both languages.
TFIDF
TF-IDF is a combination of two words, i.e. Term Frequency and Inverse Document Frequency. First, the term “term frequency” will be discussed. TF is used to determine how frequently a term appears in a document. Consider a paper called “T1” that has 5000 words in it and exactly 10 instances of the term “Alpha.” Since it is commonly known that papers can range in size from extremely brief to quite lengthy, it is possible that any term may appear more frequently in lengthy documents than in shorter ones. In order to solve this problem, the word frequency is calculated by dividing each instance of a term in a document by the total number of terms in that document. The term frequency of the word “Alpha” in the document “T1” will therefore be TF = 10/5000 = 0.002 in this instance.
The two key metrics that show the specificity and relevance of words with the information carried by the documents are term frequency (TF) and inverse document term frequency (IDF). For the n-gram features that we retrieved from the tweets in the datasets, we utilized TF-IDF weights. Our model employs word n-grams of order for the English language (1, 2). 38536 features were retrieved with this. The same 81191 attributes were obtained via character n-grams of order (1, 5). Combining character n-grams (1, 5) and word n-grams (1, 2) yielded 119727 characteristics.
The three feature extraction techniques were tested in order to determine which produced the best feature model. The three feature models mentioned above were all used in the case of Tamil. 117173 characteristics were retrieved from the word n-grams of the (1, 4) order. Word n-grams (1, 4) and character n-grams (1, 7) together have retrieved 443075 features, while the character n-grams of order (1, 7) have extracted 325902 characteristics. These n-grams can be used to identify localized, minute syntactic patterns in text using flexible language. A sample of these traits in Malayalam and Tamil language text found in the relevant datasets are shown in Tables 2 and 3, respectively.
Project Prerequisites
The requirement for this project is Python 3.6 installed on your computer. I have used Jupyter notebook for this project. You can use whatever you want.
The required modules for this project are –
- Numpy(1.22.4) – pip install numpy
- Seaborn(0.9.0) – pip install seaborn
- Keras(2.9.0) – pip install keras
- Pandas(1.5.0) – pip install pandas
That’s all we need for our project.
Hate Speech Detection Project
We will provide the dataset and source code for the hate speech detection project. For this project, we have a csv file that contains text and a label column for determining whether a text is hate speech. Please download them from the following link: Hate Speech Detection Project
Steps to Implement
1. Import the modules and all the libraries we would require in this project.
# import the required libraries
import pandas as pd #improting the pandas library
import numpy as np #importing the numpy library
import re #importing the re library of python
import seaborn as sns #importing the seaborn library of python to use in the project.
import matplotlib.pyplot as plt #importing the matplotlib library to plot the graphs in projects.
from matplotlib import style #importing the style library from matplotlib
from nltk.tokenize import word_tokenize #improting teh word_tokenize function of nltk library
from nltk.stem import WordNetLemmatizer #importing the wordNetLemmatizer function from nltk.stem to lemmatize the word
from nltk.corpus import stopwords #importing the stopwords from nltk library
stop_words = set(stopwords.words('english'))
from wordcloud import WordCloud #importing wordcloud from word cloud library of python
from sklearn.feature_extraction.text import TfidfVectorizer #importing the TfidfVectorizer from sklearn.features
from sklearn.model_selection import train_test_split #importing the test_train function from sklearn to split the data into testing and training
from sklearn.linear_model import LogisticRegression #importing the Logistic Regression from sklearn.linear library
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix, ConfusionMatrixDisplay #importing the accuracy_score, nad classification report, confusion matrix and Confusion Matrix Display
2. Here we are reading the dataset and we are creating a function to do some data processing on our dataset. This function will take string input and it will remove all the punctuation or special characters from the text.
dataframe= pd.read_csv('dataset.csv') #reading our hateDetection csv file which contains our training data
tweet_df.head() #displaying the head of our dataset.
def data_processing(data): #creating the data processing function and we are passing a sentence to it.
data= data.lower() #so our function will take a sentence as an input and we are converting it to lowercase
data= re.sub(r'\@w+|\#','', data)#preprocessing the data
data= re.sub(r'[^\w\s]','',data)#preprocessing the data
data= re.sub(r'ð','',data)#preprocessing the data
data= word_tokenize(data)#preprocessing the data
result = [w for w in data if not w in stop_words]#finding the result
return " ".join(result)#returning the result
3. Here we are creating a function for lemmatizing the string we passed as input.
dataframe.tweet = dataframe['tweet'].apply(data_processing)#preprocessing the dataframe
dataframe= dataframe.drop_duplicates('tweet')#dropping duplicate tweets
lemmatizer = WordNetLemmatizer()#creating an instance of lemmatization
def lemmatizing(data):#creating a lemmatizing function
s= [lemmarizer.lemmatize(word) for word in data]#lemmatization on data
return s
dataframe['tweet'] = dataframe['tweet'].apply(lambda x: lemmatizing(x))#applying the lambda function
non_hate_tweets = dataframe[tweet_df.label == 0]#non hate tweets data
non_hate_tweets.head()#printing the non hate tweets

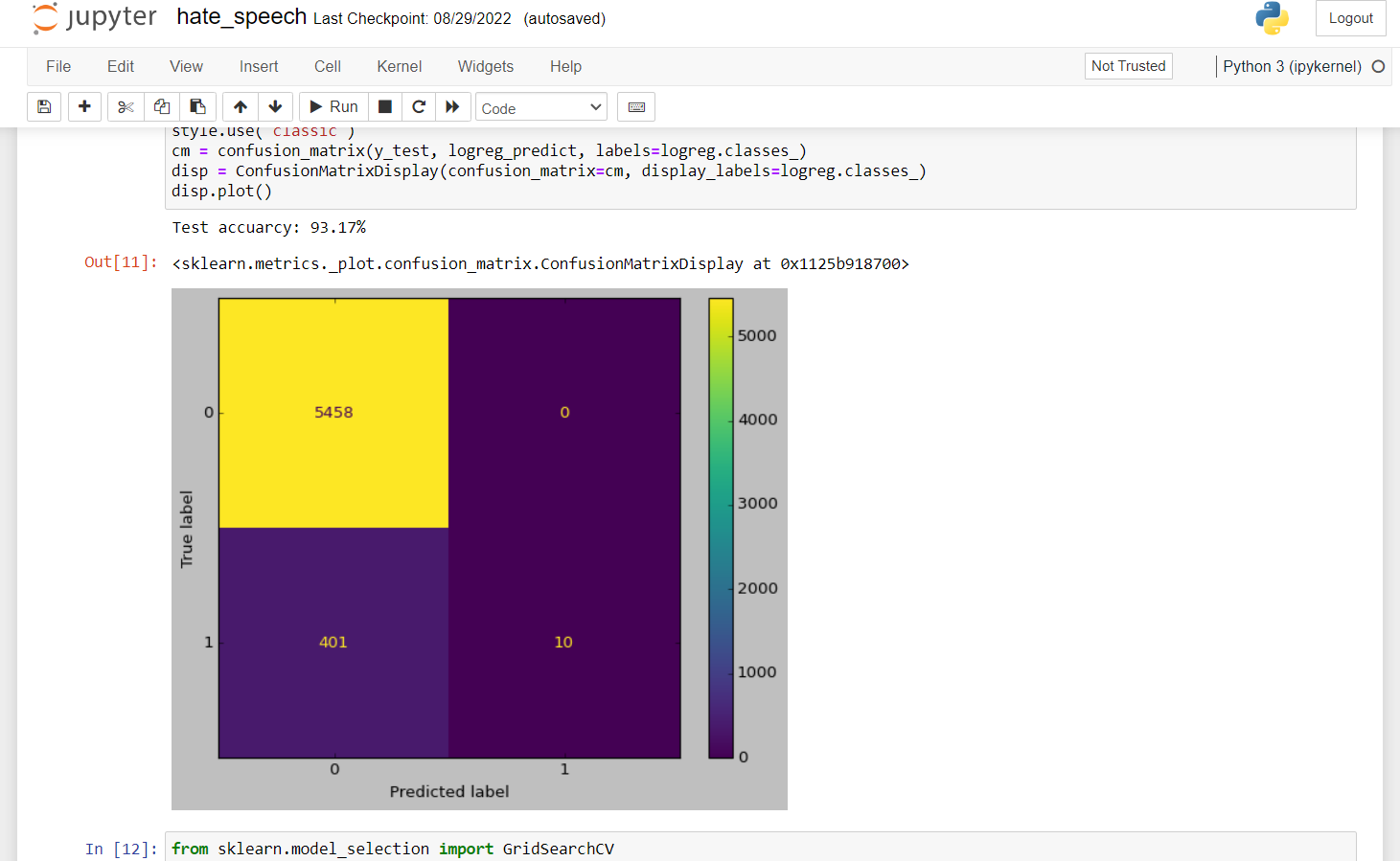
3. Here, we are creating our model, which is TfidfVectorizer and Logistic Regression. Also, we are defining our testing and training dataset. We used random_state = 42. We took the training data as 80% and the testing data as 20%. Then we pass this testing and training dataset to our model Logistic Regression, and we train the model with the training dataset. Then we test the model using the testing dataset.
vector = TfidfVectorizer(ngram_range=(1,2)).fit(dataframe['tweet'])#creating the TfidfVectorizer feat_dataframe= vector.get_feature_names()#getting the feature names from the vector vector = TfidfVectorizer(ngram_range=(1,3)).fit(dataframe['tweet'])#using the tfidfvectorizer and fitting the data into it feat_dataframe = vector.get_feature_names()#getting feature dataframe x_set = dataframe['tweet'] y_set = dataframe['label'] x_set = vect.transform(x_set) x_train, x_test, y_train, y_test = train_test_split(x_set, y_set, test_size=0.2, random_state=42) model = LogisticRegression() model.fit(x_train, y_train) pred = model.predict(x_test) accuracy_score(pred , y_test)
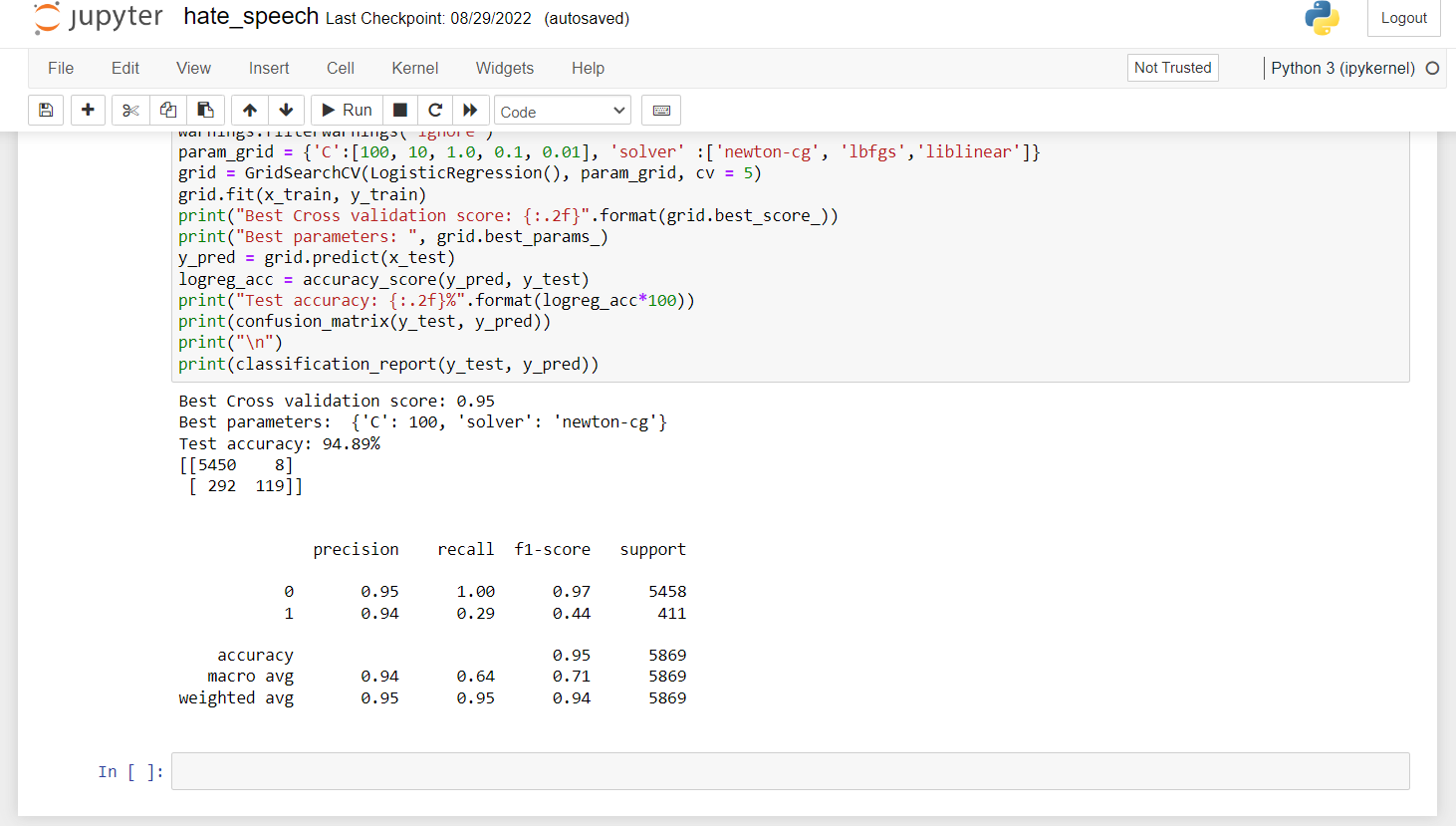
4. Here, we are defining the GridSearchCV function, and we are passing our training dataset to it. Then we pass our testing dataset to it to check the performance of our model.
from sklearn.model_selection import GridSearchCV#importing the Grid Search library
model = GridSearchCV(LogisticRegression(), {'C':[100, 10, 1.0, 0.1, 0.01], 'solver' :['newton-cg', 'lbfgs','liblinear']}, cv = 5)#creating the Grid search CV model
model.fit(x_train, y_train)
y_pred = model.predict(x_test)#predicting the model result
accuracy_score(y_pred, y_test)#printing the accuracy of the model
Summary
In this Machine Learning project, we built a hate speech detection system. In this project, we used Logistic Regression and TfidfVectorizer as models to predict the data. We hope you have learned something new in this project.
the link you have added is not working