Detecting Parkinson’s Disease with Machine Learning
We offer you a brighter future with FREE online courses - Start Now!!
What is Parkinson’s Disease?
Parkinson’s disease is a central nervous system disorder. Its symptoms occur because of low dopamine levels in the brain. Four Primary symptoms are tremor, rigidity, slow movement and balance problems. Till now no cure for Parkinson’s Disease is known, treatment aims to reduce the effects of the symptoms.
About Detecting Parkinson’s Disease Project:
In this Python machine learning project, we will build a model to detect Parkinson’s disease using one of the Classifier techniques known as RandomForestClassifier as our output contains only 1’s and 0’s. We’ll load the dataset, get the features and targets, split them into training and testing sets, and finally pass them to RandomForestClassifier for prediction.
Project Prerequisites:
Install the following libraries using pip :
pip install numpy , pandas , matplotlib , sklearn
The versions which are used in this parkinson’s Disease Detection project for python and its corresponding modules are as follows:
1) python: 3.8.5
2) numpy: 1.19.5
3) pandas: 1.1.5
4) matplotlib: 3.2.2
5) sklearn: 0.24.2
Download ML Project Code for Detecting Parkinson’s Disease
Please download the source code of detecting parkinson’s disease with machine learning: Detecting Parkinson’s Disease Project Code
Project file Structure:
parkinsons.csv: dataset file for our project.
parkinsons.py: python file where we will train our model and predict the output.
Steps for detecting Parkinson’s disease:
1) Import Libraries
Firstly we will import all the required libraries which have been shared in the prerequisites section.
Code:
#load all modules for Parkinson's Disease Detection Project import numpy as np import pandas as pd from sklearn.preprocessing import MinMaxScaler from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, mean_absolute_error, mean_squared_error import matplotlib.pyplot as plt from sklearn import tree from sklearn.ensemble import RandomForestClassifier
2) Preprocessing
Read the ‘parkinsons.csv’ file in dataframe using the ‘pandas’ library
Code:
#read csv file of parkinson's dataset
df=pd.read_csv("parkinsons.csv")
dataset file :

Fetch the features and targets from the dataframe. Features will be all columns except ‘name’ and ‘status’. Therefore we will drop these two columns. And our target will be ‘status’ column which contains 0’s(no parkinson’s disease) and 1’s(has parkinson’s disease)
Code:
#extract features but we don't want 'name' and 'status' columns #so we will drop these two columns and store remainings #axis 1 is for columns features = df.drop(['name','status'],axis=1) #our target data will be 'status' target = df.loc[:,'status']
3) Normalization
We will scale our feature data in the range of -1(minimum value) and 1(maximum value). Scaling is important because variables at different scales do not contribute equal fitting to the model which may end up creating bias. For that we will be using ‘MinMaxScaler()’ to fit and then transform the feature data.
Code:
#scale all the features data in the range between -1,1 scaler= MinMaxScaler((-1,1)) features_c=scaler.fit_transform(features)
4) Training and Testing
Split dataset into 80:20 ratio where 80 rows for training and 20 rows for testing purposes. For this we will pass scaled features and target data to ‘train_test_split()’.
Code:
#split the dataset into training and testing sets where 20% data for testing purpose. x_train,x_test,y_train,y_test = train_test_split(features_c, target , test_size=0.2,random_state=10)
5) Building the classifier model
We will use Random forest Classifier for the classification of our data points. So let’s see what random forest is.
What is a Random Forest Algorithm?
Random forest is a supervised learning algorithm. It can be used for both Classification and Regression problems. It uses an ensemble learning method known as ‘bagging’ (Bootstrap Aggregation) which is a process of combining multiple classifiers to solve a complex problem.
Random forest creates various random subsets of the given dataset and passes them to different numbers of decision trees and takes the prediction from each tree. Based on the majority votes of prediction, random forest takes the average to predict the output and also to increase the accuracy and overall result. As there are greater numbers of trees in random forests, it prevents the problem of overfitting.
Random forest searches for the most important feature while splitting a node which helps in building a better model.
Random forest example:
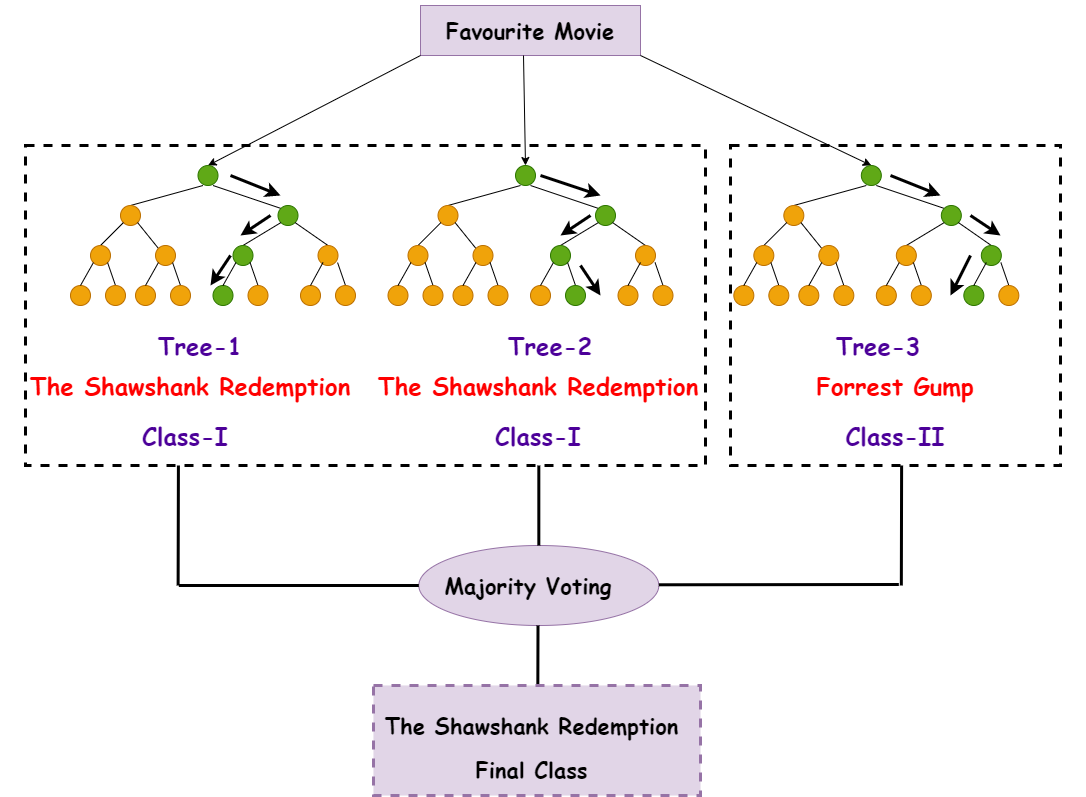
As you can see in the above image we are building a random forest for the topic “Favourite movie”. We have used three trees for the classification. Let’s say these three trees are three different persons. So after asking different questions and applying the conditions we can see that the first two people said their favorite movie is “The Shawshank Redemption” and one said “Forrest Gump”.
As Random forest classifier uses majority voting technique, we get “The Shawshank Redemption” as our Final Class output.
Initialize ‘RandomForestClassifier’ and train the model.
Code:
#initialize the random forest classifier and fit the datas model= RandomForestClassifier(random_state=2) model.fit(x_train,y_train)
Output:

After we train our model we can see how RandomForestClassifier fits our features and targets of the dataset. We will plot the first 5 trees of our classifier using the ‘matplotlib’ library.
Code:
#plot the RandomForestClassifier’s first 5 trees
fig, axes = plt.subplots(nrows = 1,ncols = 5,figsize = (10,2), dpi=900)
for index in range(0, 5):
tree.plot_tree(model.estimators_[index],feature_names= features.columns,
class_names= 'status',filled = True,ax = axes[index])
axes[index].set_title('Estimator: ' + str(index+1), fontsize = 11)
fig.savefig('Random Forest 5 Trees.png')
6) Prediction and Accuracy
Now we will predict our output(y_pred) for testing data(x_test) which is 20% of the dataset using the model which we have trained. Also, we will calculate accuracy, mean absolute error and root mean square error of our model.
Code:
#predict the output for x_test
y_pred=model.predict(x_test)
#calculate accuracy,root mean squared error
print('Accuracy :',accuracy_score(y_test, y_pred))
print('Mean Absolute Error:', mean_absolute_error(y_test, y_pred))
print('Root Mean Squared Error:', np.sqrt(mean_squared_error(y_test, y_pred)))
Output:

7) Building the Prediction System.
Finally, we will take the user’s input and check whether data has Parkinson’s disease or not.
Code:
#input data and transform into numpy array
in_data= np.asarray(tuple(map(float,input().rstrip().split(','))))
#reshape and scale the input array
in_data_re = in_data.reshape(1,-1)
in_data_sca = scaler.transform(in_data_re)
#print the predicted output for input array
print("Parkinson's Disease Detected" if model.predict(in_data_sca) else "No Parkinson's Disease Detected")
Detect Parkinson’s Disease Output

Summary
In this Machine learning project, we developed a model using the RandomForestClassifier of the sklearn module of python to detect if an individual has Parkinson’s Disease or not. We got the machine learning model with 97.43% accuracy, which is good as our dataset contains less records.
It’s amazing to read that Parkinson’s disease can now be detected at its early stage through a machine learning project that analyzes and predicts symptoms based on your personal data. I am really all for supporting technology that can improve our medical services.