Credit Card Fraud Detection using Python & Machine Learning
FREE Online Courses: Click for Success, Learn for Free - Start Now!
In this article, we are going to develop Machine Learning Credit Card Fraud Detection project in easy steps. Let’s start!!
What is Credit Card Fraud Detection?
Nowadays most people prefer to do payments by cards and don’t like to carry cash with them. That leads to an increase in the use of cards and also thereby frauds.
Credit card frauds are easy to do, as we know that E-commerce and many other online sites have increased the online payment modes, Which affects increasing the risk of online frauds.
Credit card fraud is becoming the most common fraud people tend to do. So in this article by ProjectGurukul we are going to detect credit card fraud using Machine Learning.
About Credit Card Fraud Detection Project:
We need to find anomalies in the system for the companies that have a lot of transactions with the use of cards.
The project aims to build a credit card fraud detection model, which tells us if the transaction made by the card is fraud or not. So basically we will use the transaction and their labels as fraud or non-fraud to detect if the new transaction made by the customer is fraud or not.
To prevent customers from being charged for the items they did not purchase, It is important for credit card companies to recognize fraudulent credit card transactions.

Challenges we need to face while creating this project:
- As we know that a large amount of data is processed every day, the model we have to create must be fast enough to respond to the scam in time.
- We will be having imbalanced data in which most of the transactions are actual transactions not fraud one which makes it really hard for detecting the fraud ones.
- We have to search for a dataset, as credit card data is mostly private.
- Another major issue will be misclassified data, as not every fraudulent transaction is caught and reported.
How will we be tackling these challenges:
- The model we will create will be very simple and fast enough to detect the anomaly and can identify which transaction is actual and which one is fraud.
- We will use proper methods to deal with imbalanced data that we will discuss below.
- For the privacy of the user dataset, we will reduce the dimensionality of the data.
- We will use a dataset from a trustworthy source at least for training the model.
Dataset
In credit card fraud detection project, we will use the dataset which is a csv file. The dataset consists of transactions that occurred in two days, where there are 492 frauds out of 284,807 transactions. The dataset is highly unbalanced i.e in this most of the transactions are actual transactions not the fraud one.
You can directly download the dataset by clicking on the link given below: Credit Card Dataset
Credit Card Fraud Detection Machine Learning Project Code
To learn and implement credit card fraud detection please download the zip which consists of a source folder: Credit Card Fraud Detection Project
Required Libraries for ML Credit Card Fraud Detection Project:
To create a “Credit card fraud detection project” you need to install some libraries in your system. The libraries are:
- Numpy
- Pandas
- Matplotlib
- Seaborn
- Sklearn
You can install it using pip, open your command prompt and type:
pip install numpy pandas matplotlib seaborn sklearn
Steps that we follow to create this Project is:
- We will perform exploratory data analysis on our dataset,
- After making the dataset ready we will create a model using Machine Learning Algorithm. We are going to use the Logistic Regression method to detect credit card frauds.
- At last, we will Train and Evaluate our Logistic Regression model.
About Logistic Regression:
Logistic regression is a type of Supervised learning technique. It is the most popular Machine Learning algorithm, which is used to predict the probability of target variables. Logistic regression predicts the output of a categorical dependent variable which means there would be only two possible classes.
This is one of the simplest Machine Learning algorithms used for various classification problems such as spam detection, cancer detection etc.
Now without any further delay let’s start implementing Credit Card fraud Detection using Machine learning.
1.) Importing Libraries:
The first step of all the projects will be always importing the required libraries.
# import libraries for ProjectGurukul Credit Card Fraud Detection Project using Machine Learning: import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import confusion_matrix , accuracy_score, classification_report
2.) Load the dataset:
Load the dataset we have downloaded above which is creditcard.csv file.
#Loading the dataset to a Pandas Dataframe
credit_card_data = pd.read_csv('creditcard.csv')
3.) Analysing and Visualizing the dataset:
In this step we will analyze the dataset and perform certain operations to clean the data and make it ready, to train our model. And also we will visualize the dataset.
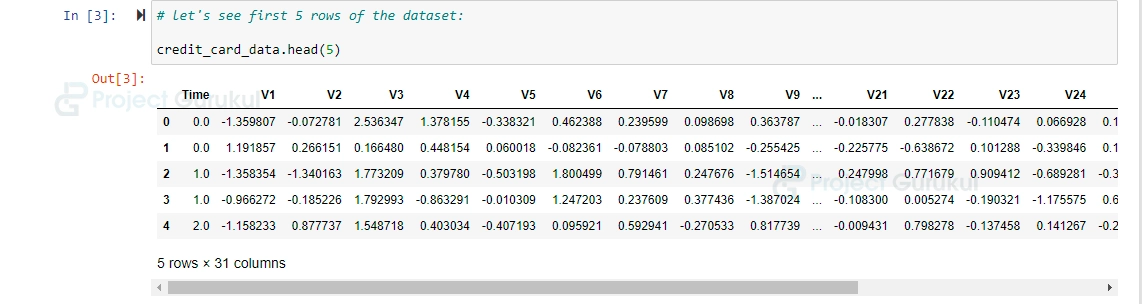
# let's see first 5 rows of the dataset: credit_card_data.head(5)
# let's see last 5 rows of our dataset: credit_card_data.tail()
# dataset information: credit_card_data.info()

# checking number of missing values: credit_card_data.isnull().sum() # Find distribution of Normal transaction or Fraud transaction: credit_card_data['Class'].value_counts()

Now we will separate Normal and Fraud transactions, and analyze and visualize that fraud and normal data :
# Separating the data:
normal = credit_card_data[credit_card_data.Class == 0]
fraud = credit_card_data[credit_card_data.Class == 1]
# check shape
print(normal.shape)
print(fraud.shape)
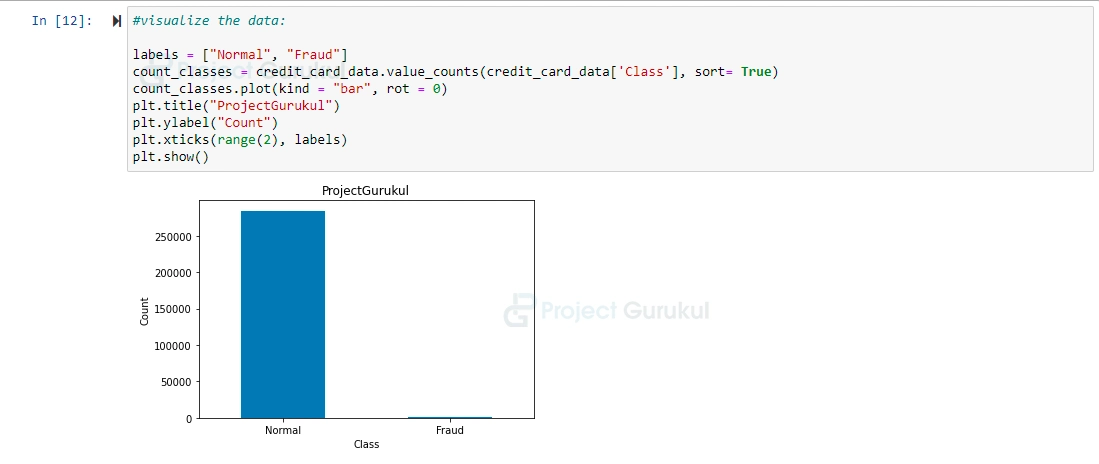
#visualize the data:
labels = ["Normal", "Fraud"]
count_classes = credit_card_data.value_counts(credit_card_data['Class'], sort= True)
count_classes.plot(kind = "bar", rot = 0)
plt.title("ProjectGurukul")
plt.ylabel("Count")
plt.xticks(range(2), labels)
plt.show()
We will perform some statistical analysis of the data:
# statistical measures of the data: normal.Amount.describe() fraud.Amount.describe() # visualize the data using seaborn: sns.relplot(x = 'Amount' , y = 'Time' , hue = 'Class', data = credit_card_data)

We are just performing Exploratory data analysis, just follow along to understand the dataset better. And make it better so that our model can detect fraud and normal transactions accurately and efficiently.
# Compare values of both transactions:
credit_card_data.groupby('Class').mean()
# Now we will build a sample dataset containing similar distribution of normal transaction and fraud transaction:
normal_sample = normal.sample(n=492)
# Concat two data ( normal_sample and fraud) to create new dataframe which consist equal number of fraud transactions and normal transactions, In this way we balance our dataset (As our dataset is highly unbalanced initially) :
credit_card_new_data = pd.concat([normal_sample, fraud], axis=0)
Let’s see our new dataset:
credit_card_new_data
# Analyse our new dataset:
credit_card_new_data['Class'].value_counts()
4) Splitting the data:
After analyzing and visualizing our data, now we will split our dataset in X and Y or say in features and labels:
# Splitting data into features and targets
X = credit_card_new_data.drop('Class', axis=1)
Y = credit_card_new_data['Class']
# splitting the data into training and testing data:
X_train, X_test, Y_train, Y_test = train_test_split(X,Y, test_size = 0.2, stratify = Y, random_state= 2)
print(X.shape, X_train.shape, X_test.shape)
5.) Creating Logistic Regression Model:
Now we will create the machine learning model.
# Creating Model: model = LogisticRegression() # training the Logistic Regression model with training data: model.fit(X_train,Y_train)
6.) Model Evaluation:
After fitting the data into the model we have to perform model evaluation to check the accuracy of the model.
# Model Evaluation
X_train_pred = model.predict(X_train)
training_data_accuracy = accuracy_score(X_train_pred, Y_train)
print('Accuracy of Training data:', training_data_accuracy)

As you can see the model we have created gives 95% accuracy on training data. The accuracy is very good as we are training our model on very less data. So on considering that our model accuracy is good.
# classification report of the model on training data: print(classification_report(X_train_pred, Y_train))
Now evaluating our model on test data:
# accuracy on test data:
X_test_pred = model.predict(X_test)
test_data_accuracy = accuracy_score(X_test_pred, Y_test)
print('Accuracy of Testing data:', test_data_accuracy)
# confusion matrix and classification report of test data:
print(confusion_matrix(X_test_pred, Y_test))
print(classification_report(X_test_pred, Y_test))

As you can see our model accuracy on test data is 92%.
So this is all about Credit Card Fraud Detection. We have created a model which can considerably detect the ‘Normal’ or ‘Fraud’ Transaction accurately and efficiently.
Summary
This is a Machine Learning credit card fraud detection project in which we have successfully created a model that can detect that the transaction made by the person is Normal or fraudulent. In this project, we learned how to perform exploratory data analysis. And also we have learned how to handle highly unbalanced datasets using sampling. Also learned about Logistic Regression and how to create a Logistic Regression model.
Thank you very much for the lesson you gave me, it’s a very good lesson!! But I will be happy if you include all the algorithms in this title and send me/share them.