Create & Execute First Hadoop MapReduce Project in Eclipse
FREE Online Courses: Knowledge Awaits – Click for Free Access!
This article will provide you the step-by-step guide for creating Hadoop MapReduce Project in Java with Eclipse. The article explains the complete steps, including project creation, jar creation, executing application, and browsing the project result.
Let us now start building the Hadoop MapReduce WordCount Project.
Hadoop MapReduce Project in Java With Eclipse
Prerequisites:
- Hadoop 3: If Hadoop is not installed on your system, then follow the Hadoop 3 installation guide to install and configure Hadoop.
- Eclipse: Download Eclipse
- Java 8: Download Java
Here are the steps to create the Hadoop MapReduce Project in Java with Eclipse:
Step 1. Launch Eclipse and set the Eclipse Workspace.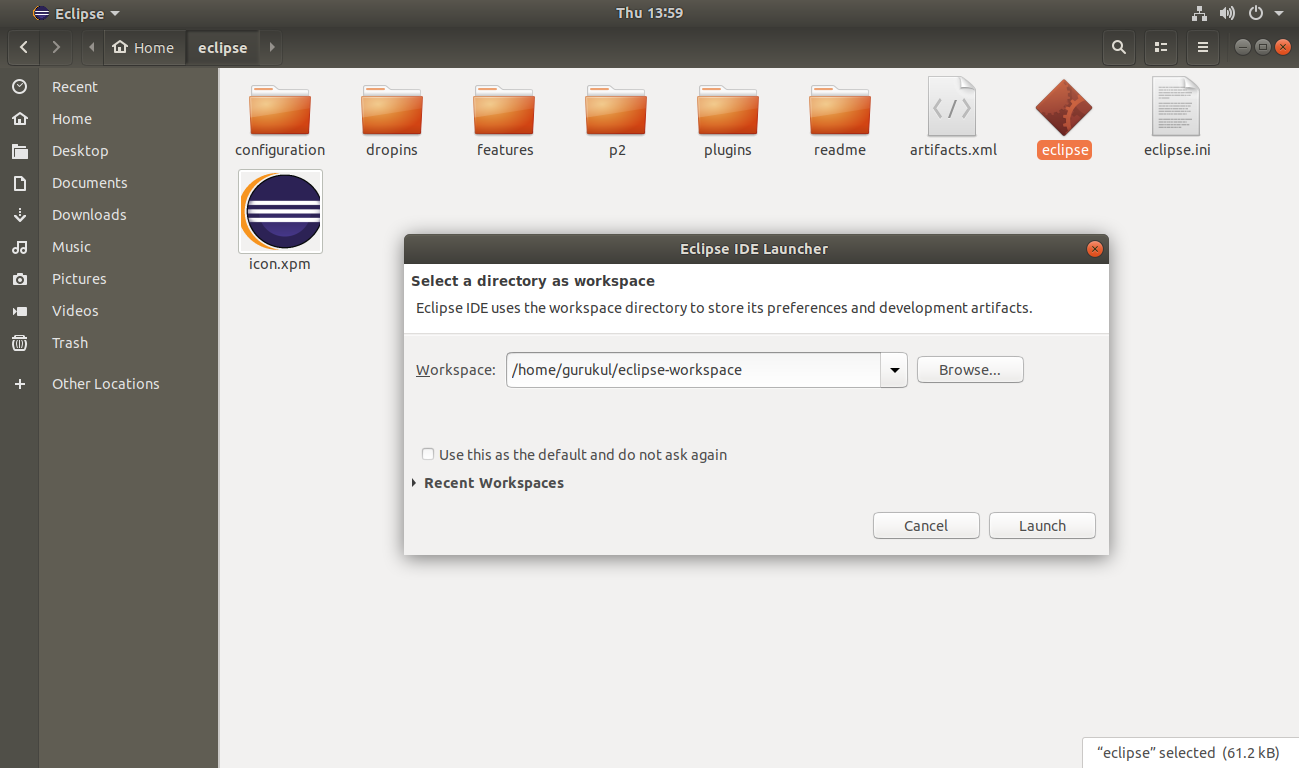
Step 2. To create the Hadoop MapReduce Project, click on File >> New >> Java Project.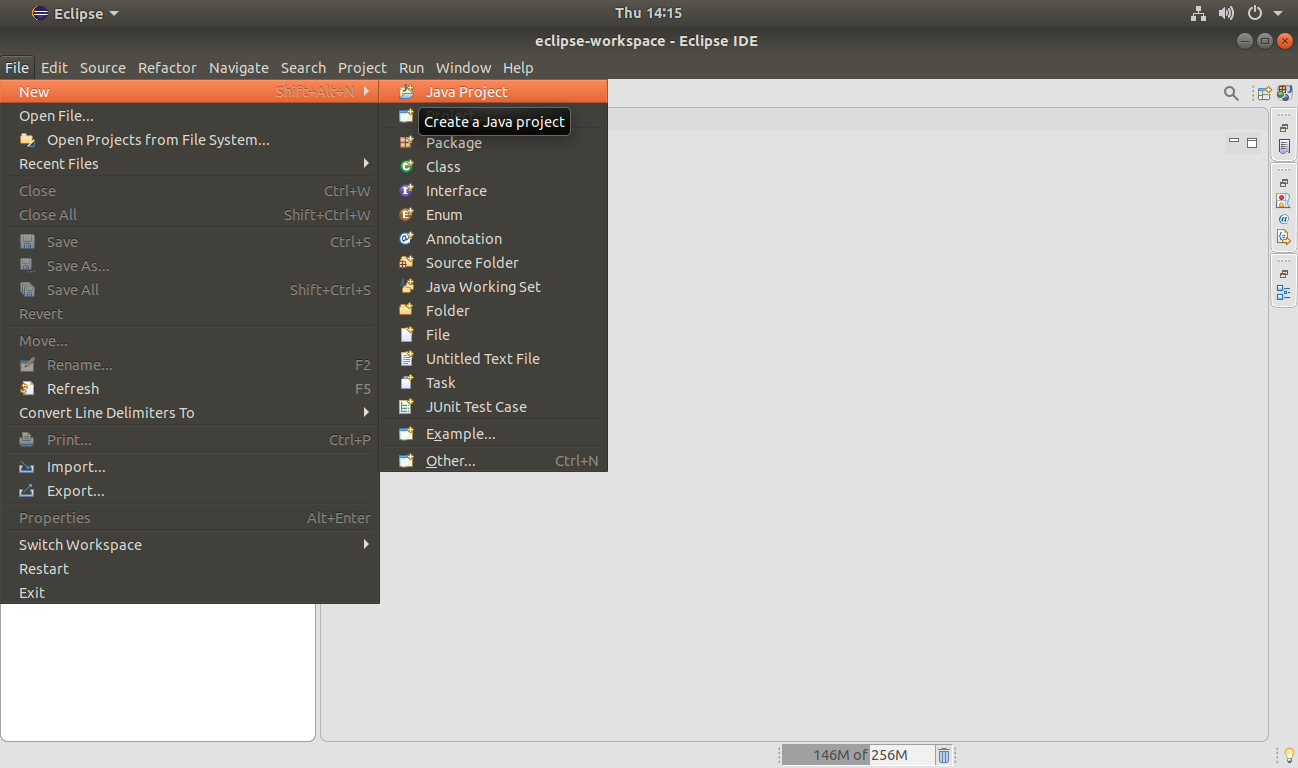
Provide the Project Name: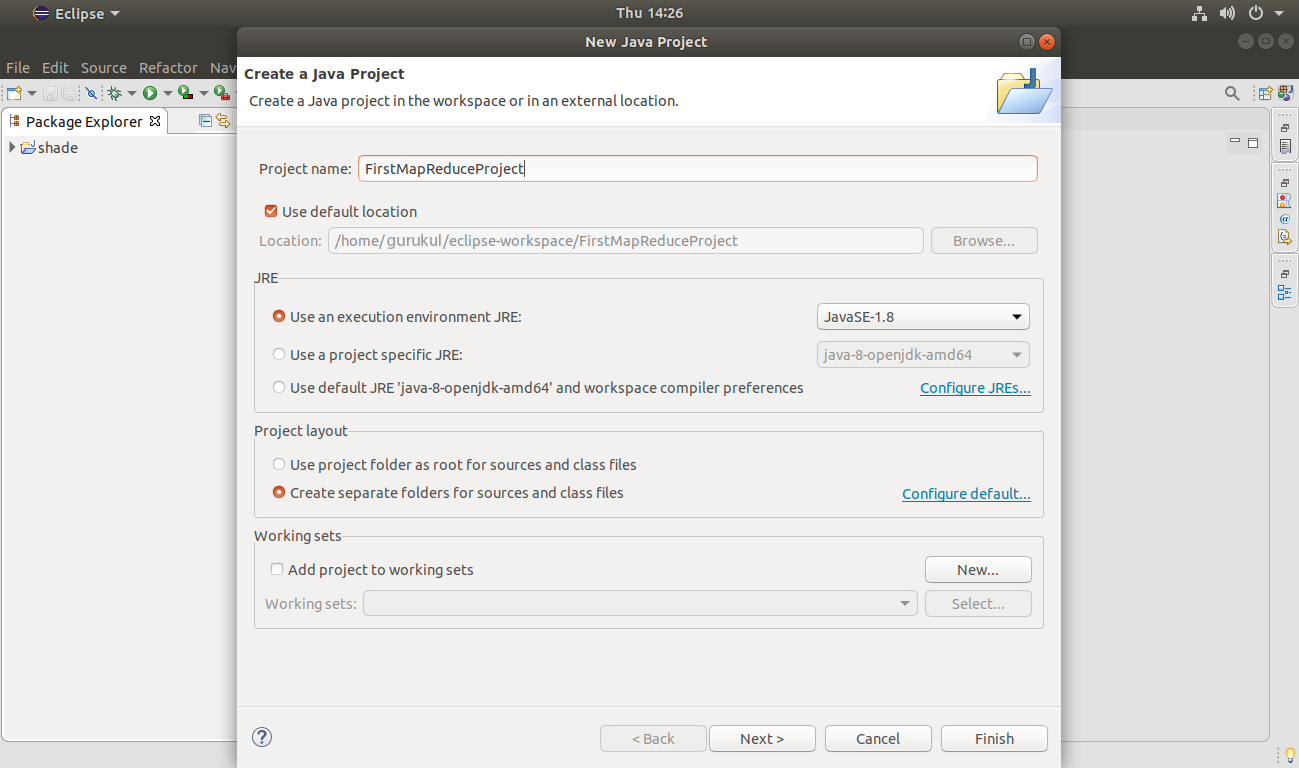
Click Finish to create the project.
Step 3. Create a new Package right-click on the Project Name >> New >> Package.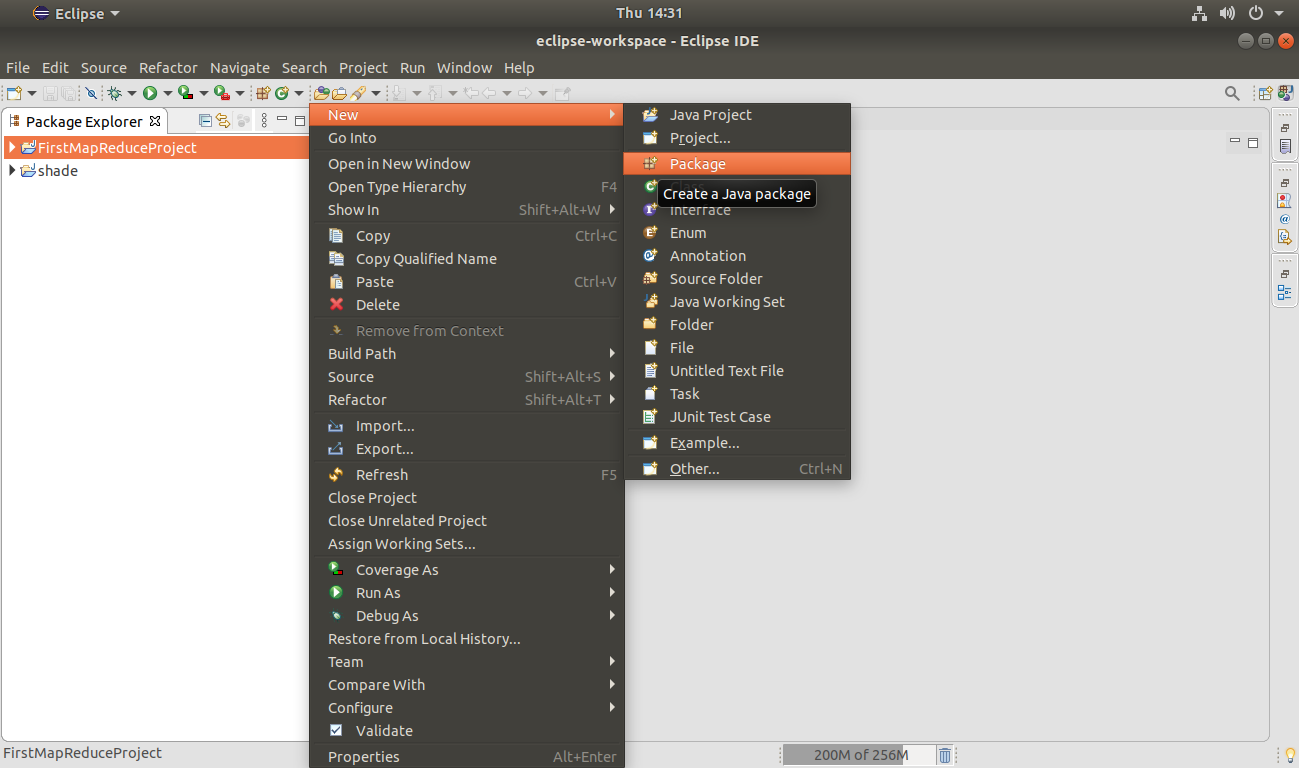
Provide the package name: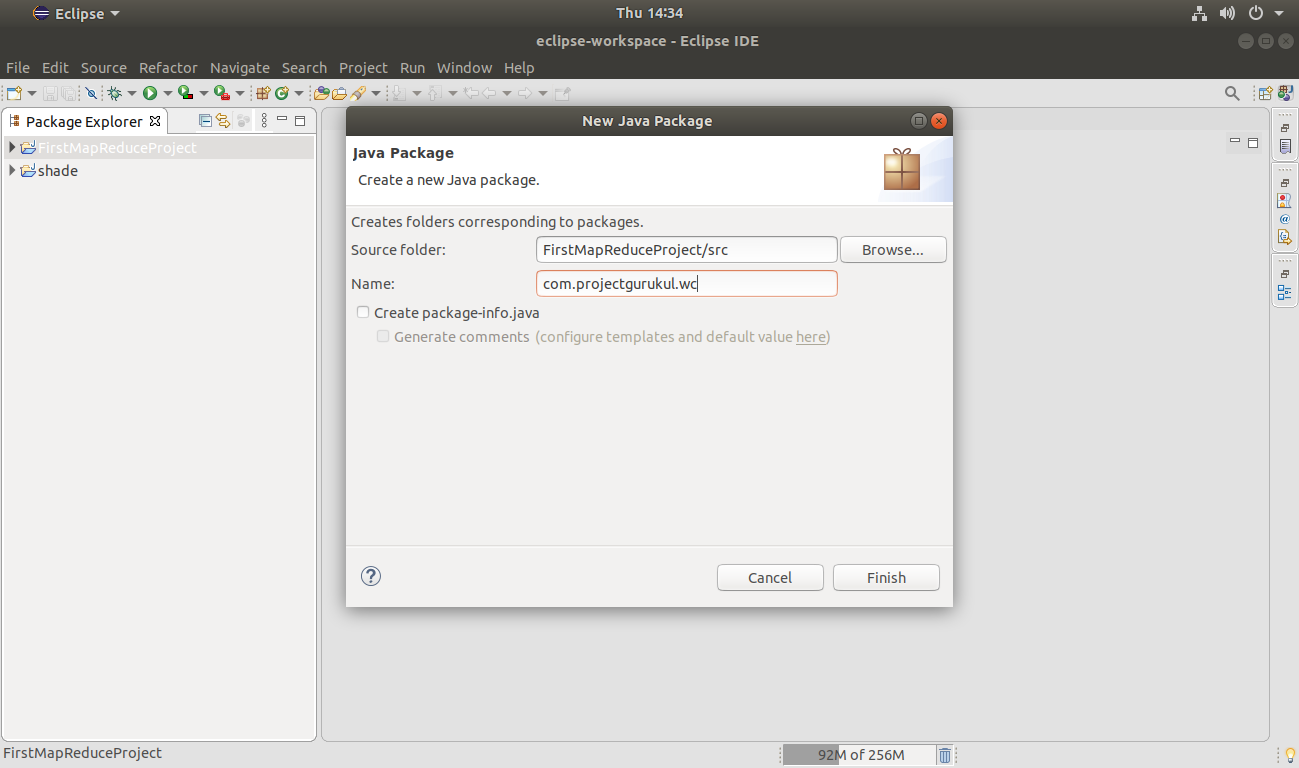
Click Finish to create the package.
Step 4. Add the Hadoop libraries (jars).
To do so Right-Click on Project Name >>Build Path>> configure Build Path.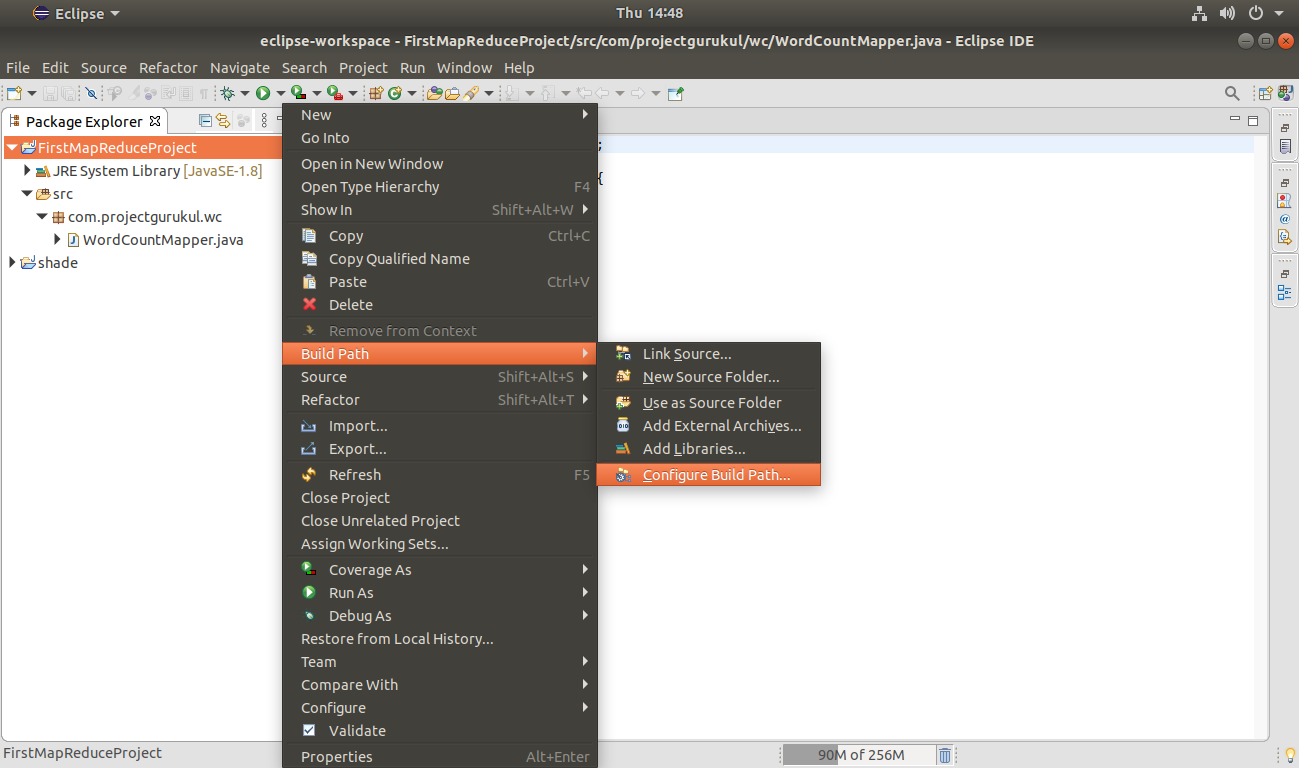
Add the External jars.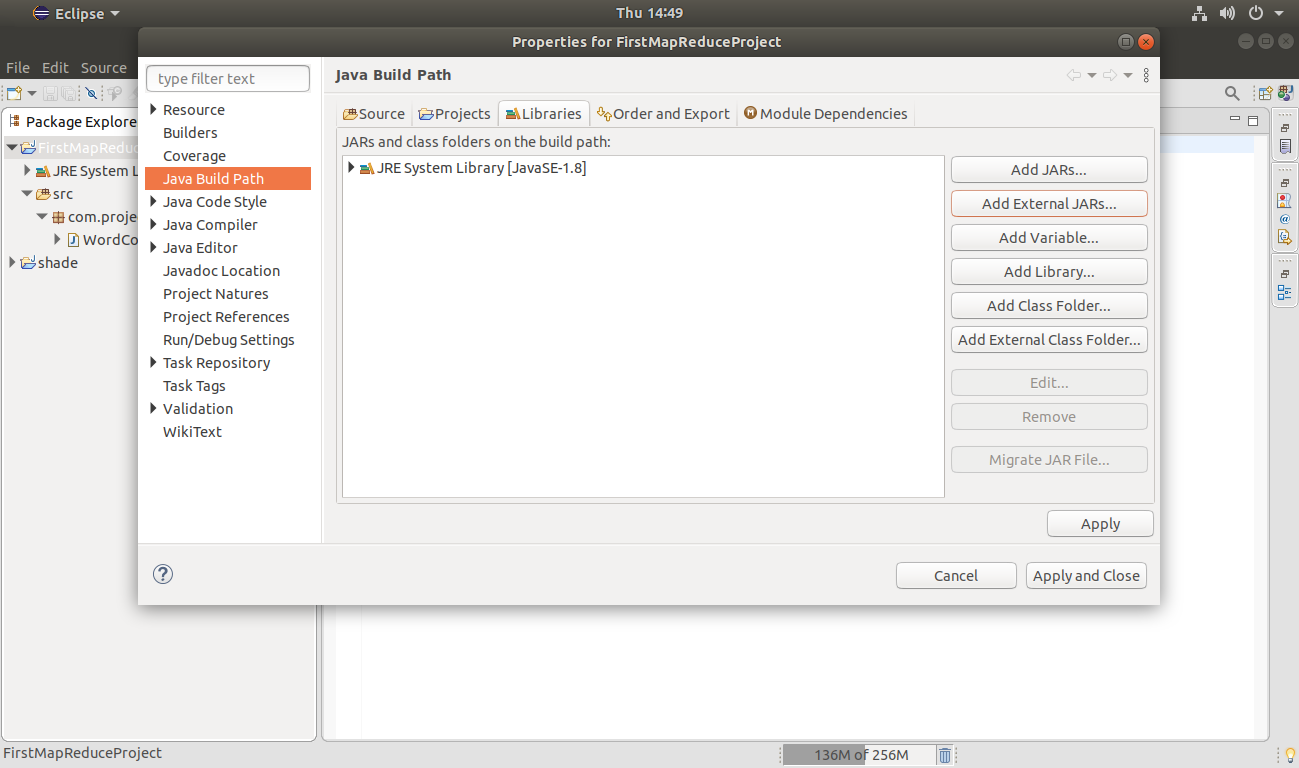
For this go to hadoop-3.1.2>> share >> hadoop.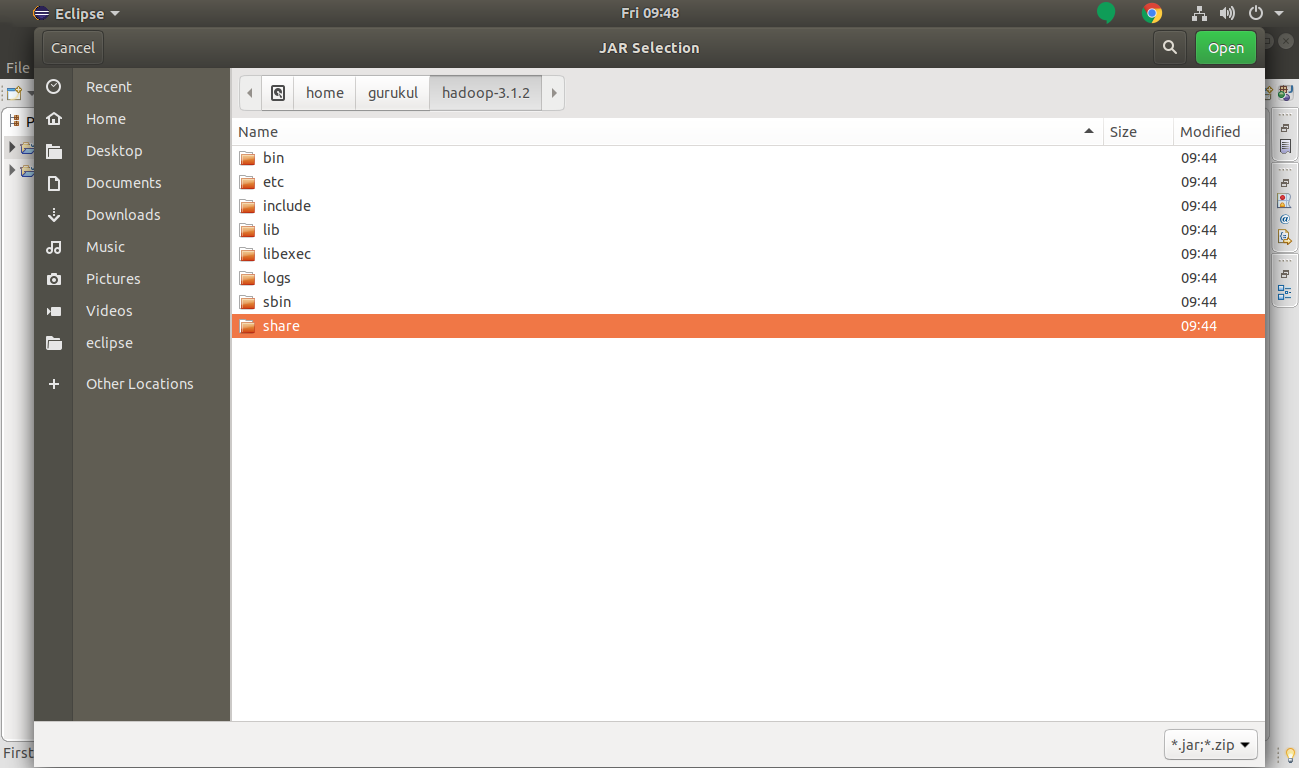
Now we will move to share >> Hadoop in Hadoop MapReduce Project.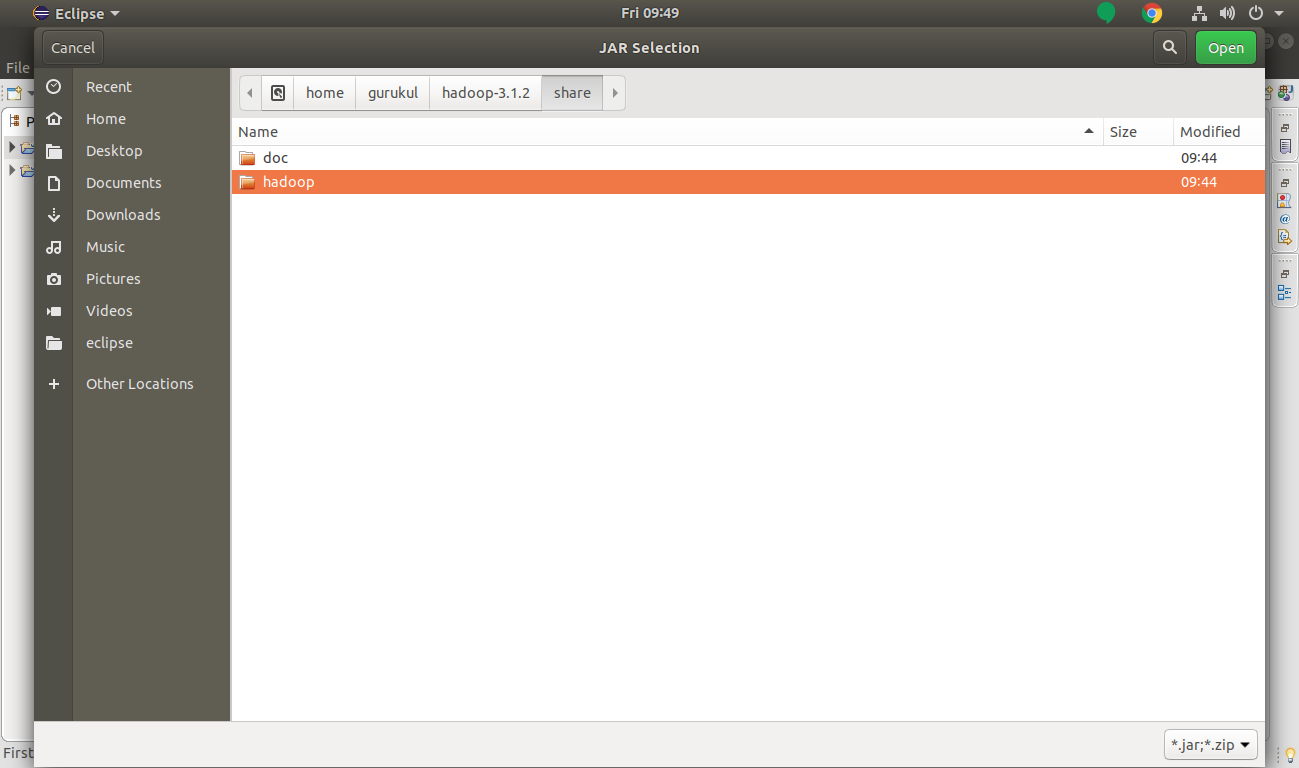
A. Add the client jar files.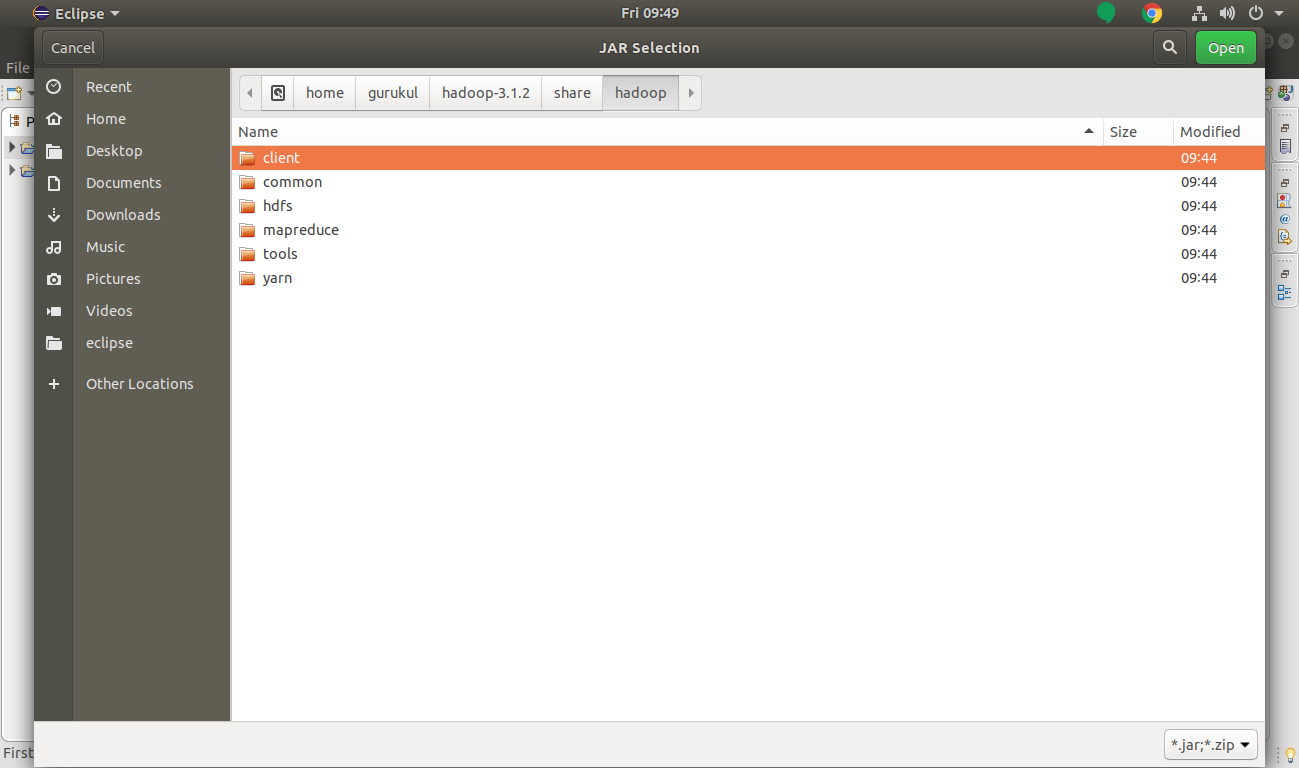
Select client jar files and click on Open.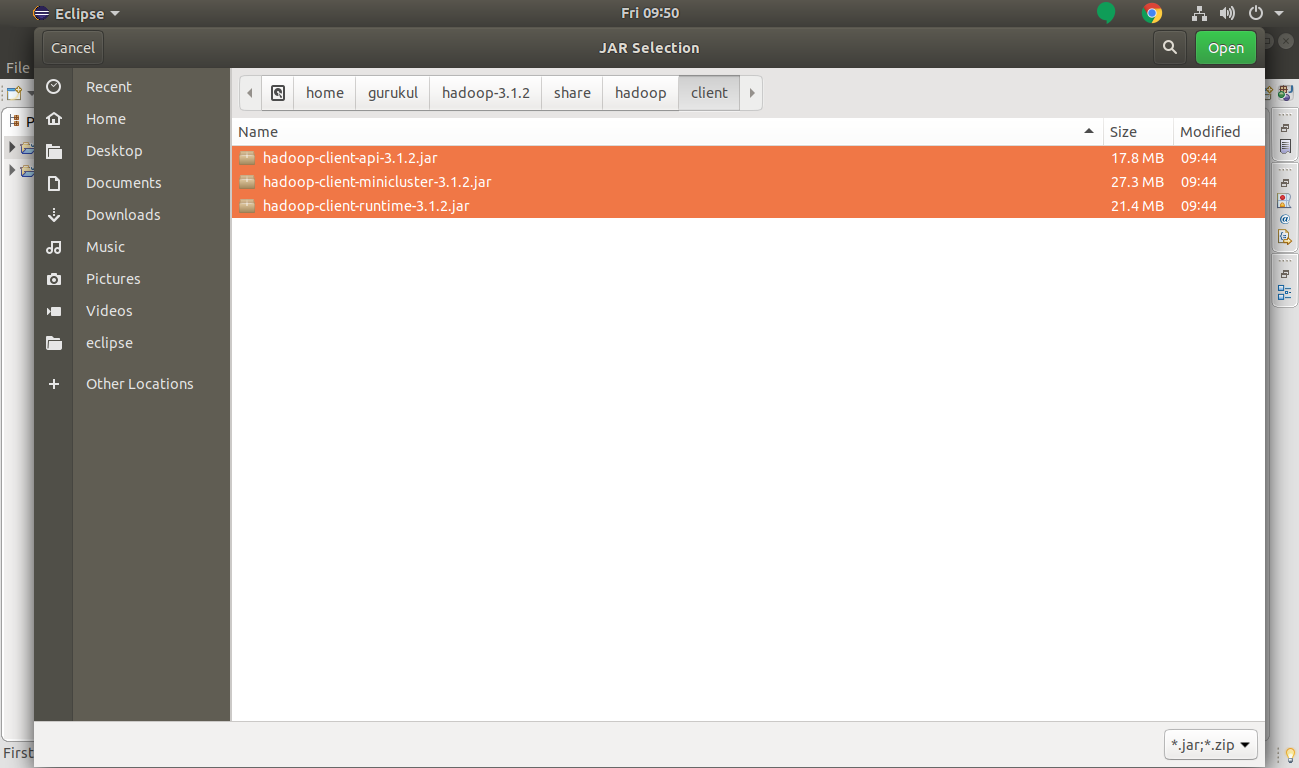
B. Add common jar files.
Select common jar files and Open.
Also, add common/lib libraries.
Select all common/lib jars and click Open.
C. Add yarn jar files.
Select yarn jar files and then select Open.
D. Add MapReduce jar files.
Select MapReduce jar files.
Click Open.
E. Add HDFS jar files.
Select HDFS jar files and click Open.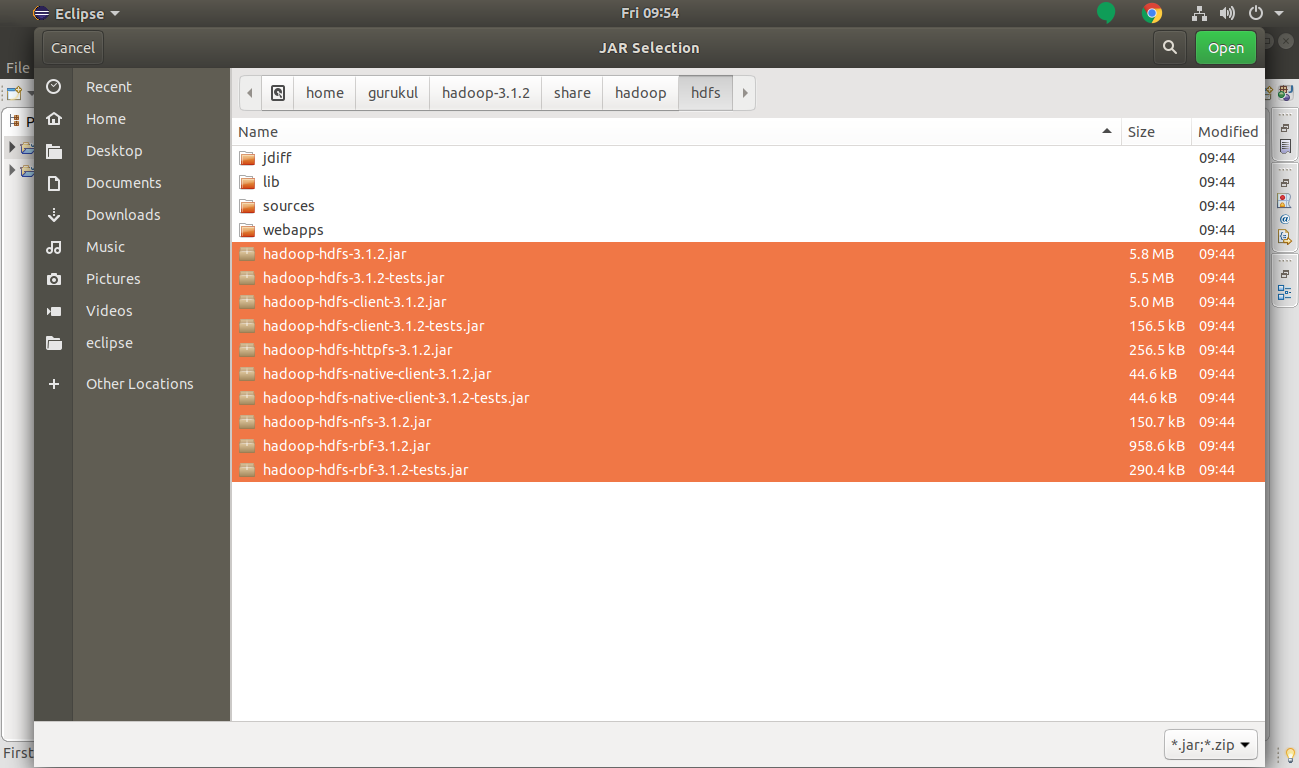
Click on Apply and Close to add all the Hadoop jar files.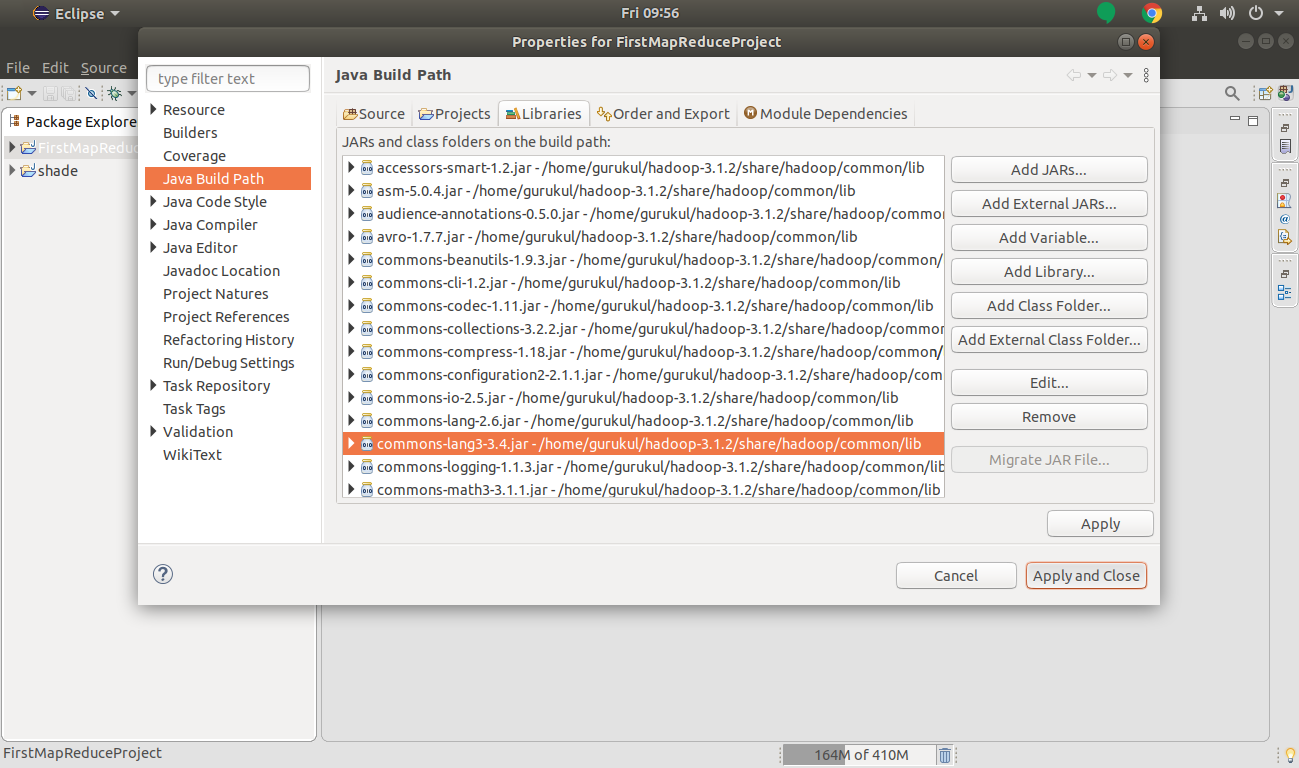
Now, we have added all required jar files in our project.
Step 5. Now create a new class that performs the map job.
Here in this article, WordCountMapper is the class for performing the mapping task.
Right-Click on Package Name >> New >> Class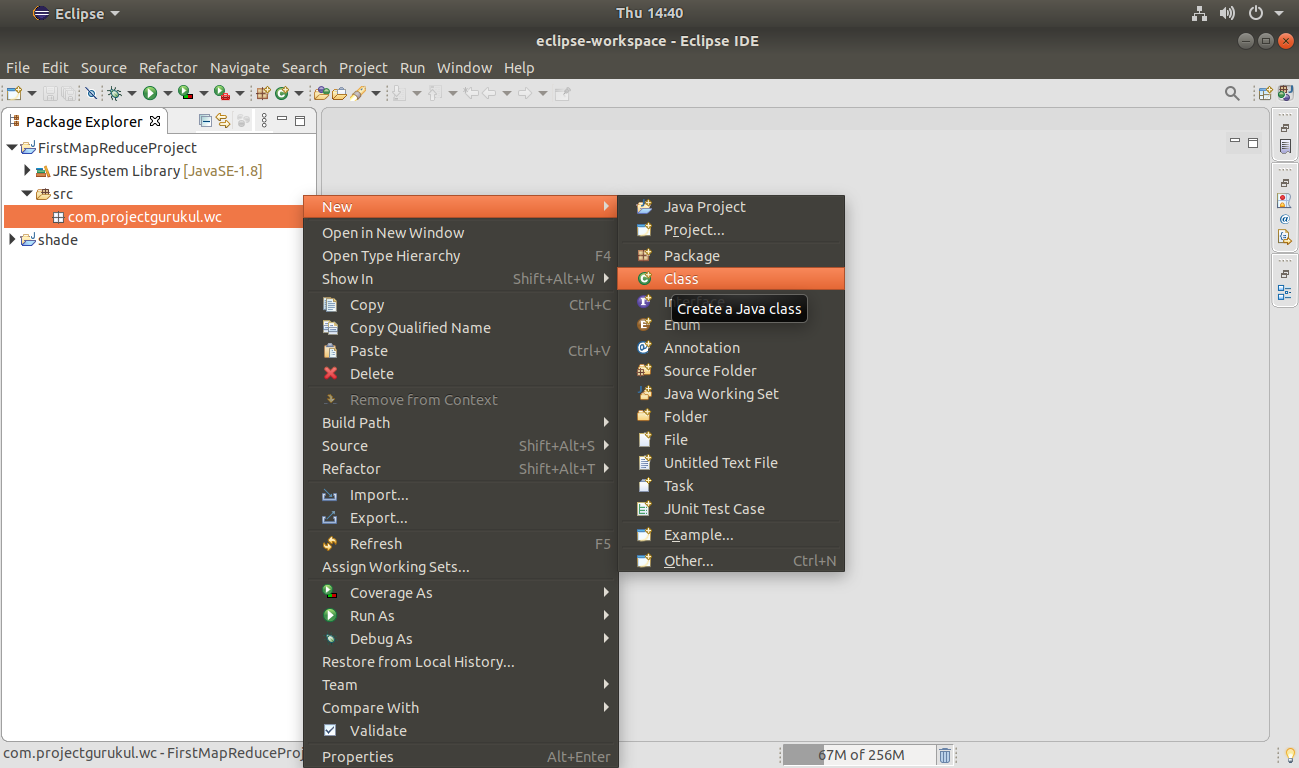
Provide the class name: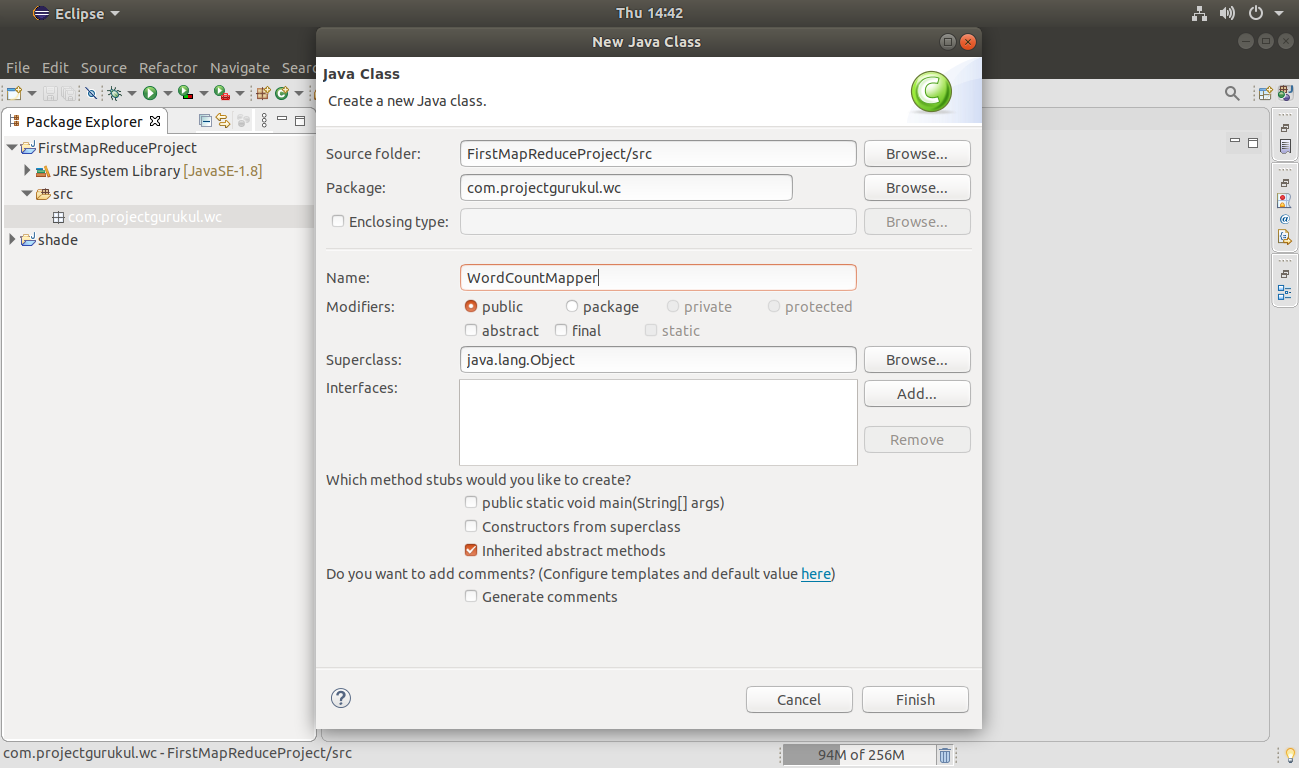
Click Finish.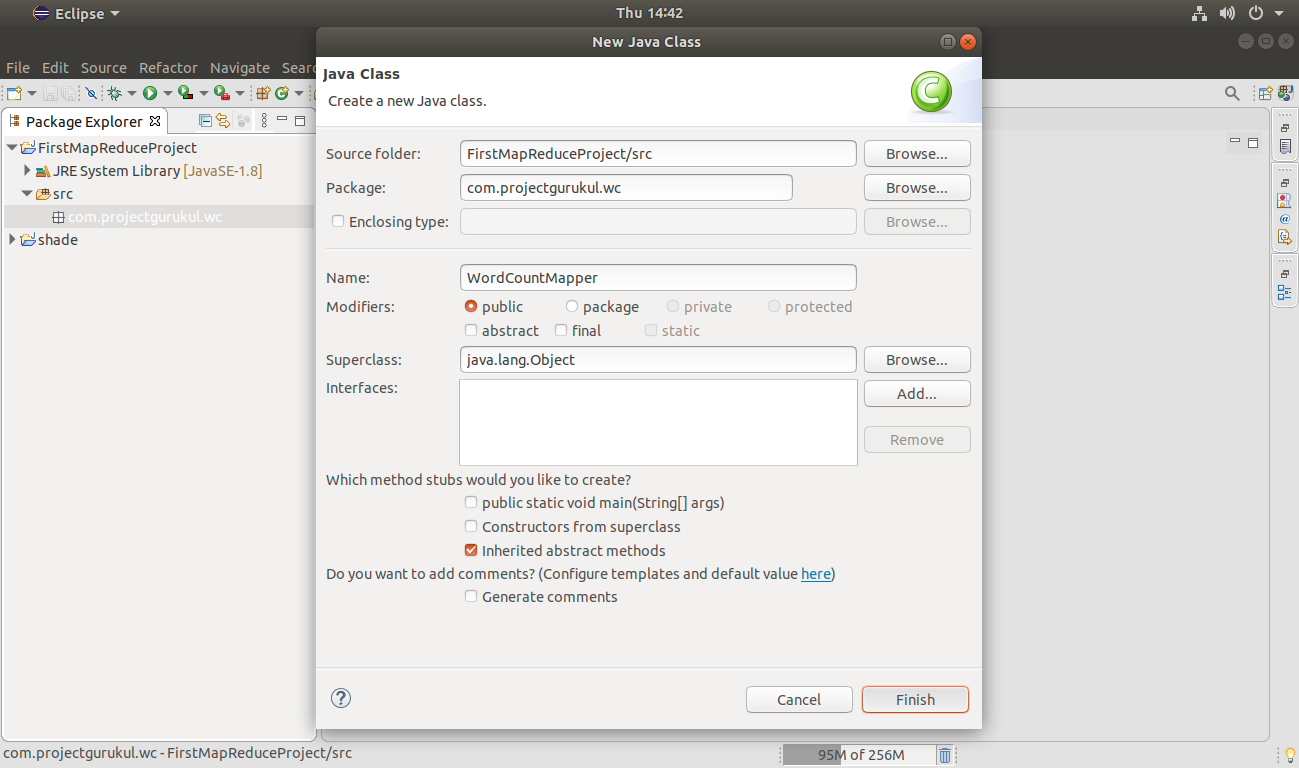
Step 6. Copy the below code in your class created above for the mapper.
package com.projectgurukul.wc;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.io.LongWritable;
public class WordCountMapper extends Mapper <LongWritable, Text, Text, IntWritable>
{
private Text wordToken = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer tokens = new StringTokenizer(value.toString()); //Dividing String into tokens
while (tokens.hasMoreTokens())
{
wordToken.set(tokens.nextToken());
context.write(wordToken, new IntWritable(1));
}
}
}
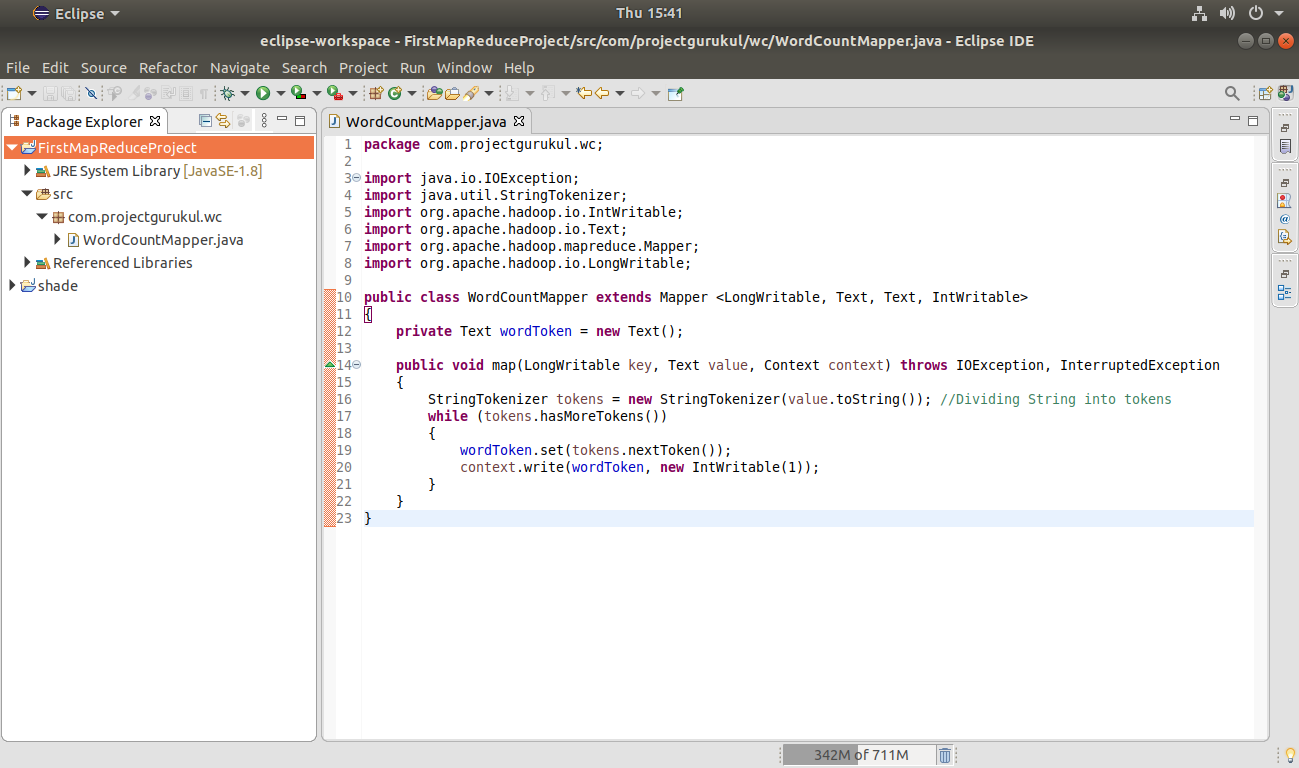
Press Ctrl+S to save the code.
Step 7. Now create another class (in the same way as we used above), for creating a class that performs the reduce job.
Here in this article, WordCountReducer is the class to perform the reduce task.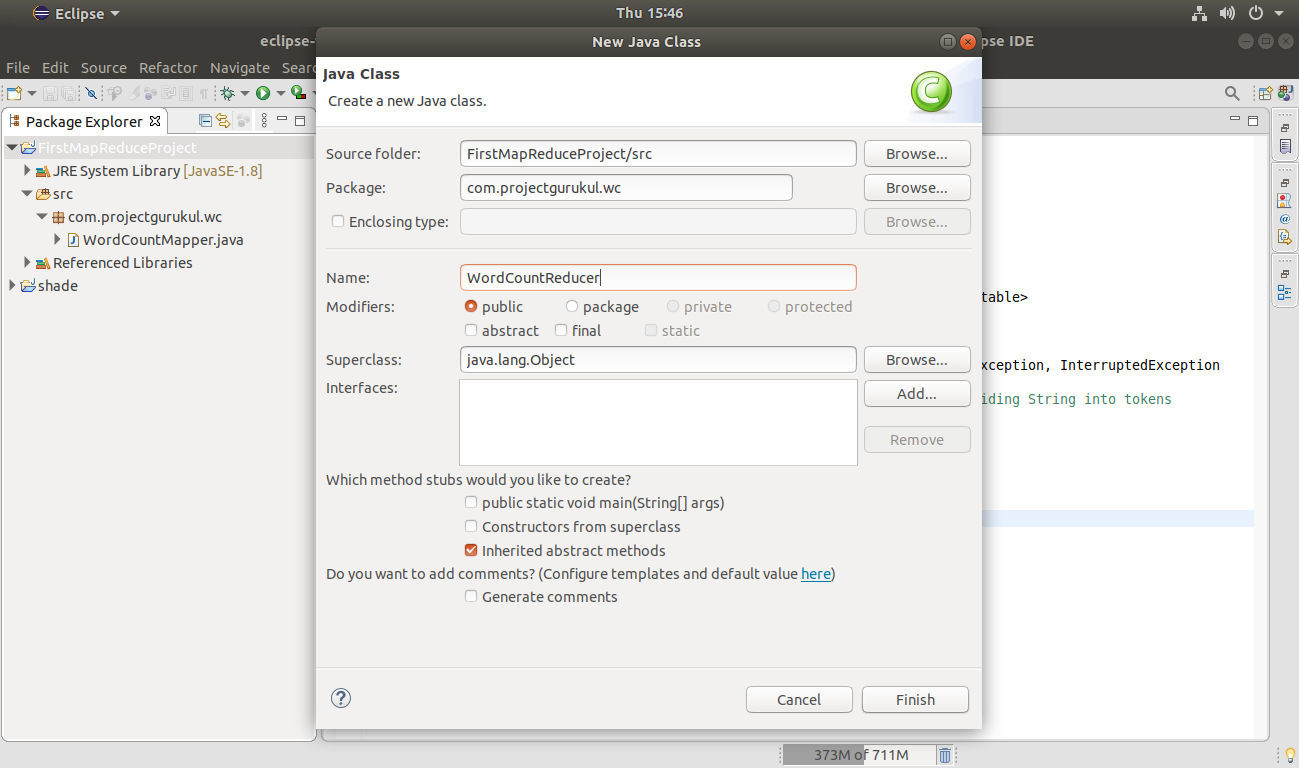
Click Finish.
Step 8. Copy the below code in your class created above for the reducer.
package com.projectgurukul.wc;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer <Text, IntWritable, Text, IntWritable>
{
private IntWritable count = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
// gurukul [1 1 1 1 1 1....]
int valueSum = 0;
for (IntWritable val : values)
{
valueSum += val.get();
}
count.set(valueSum);
context.write(key, count);
}
}

Press Ctrl+S to save the code.
Step 9. Now create the driver class, which contains the main method. Here in this article, the driver class for the project is named “WordCount”.
Click Finish.
Step 10. Copy the below code in your driver class, which contains the main method.
package com.projectgurukul.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount
{
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
String[] pathArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (pathArgs.length < 2)
{
System.err.println("MR Project Usage: wordcount <input-path> [...] <output-path>");
System.exit(2);
}
Job wcJob = Job.getInstance(conf, "MapReduce WordCount");
wcJob.setJarByClass(WordCount.class);
wcJob.setMapperClass(WordCountMapper.class);
wcJob.setCombinerClass(WordCountReducer.class);
wcJob.setReducerClass(WordCountReducer.class);
wcJob.setOutputKeyClass(Text.class);
wcJob.setOutputValueClass(IntWritable.class);
for (int i = 0; i < pathArgs.length - 1; ++i)
{
FileInputFormat.addInputPath(wcJob, new Path(pathArgs[i]));
}
FileOutputFormat.setOutputPath(wcJob, new Path(pathArgs[pathArgs.length - 1]));
System.exit(wcJob.waitForCompletion(true) ? 0 : 1);
}
}
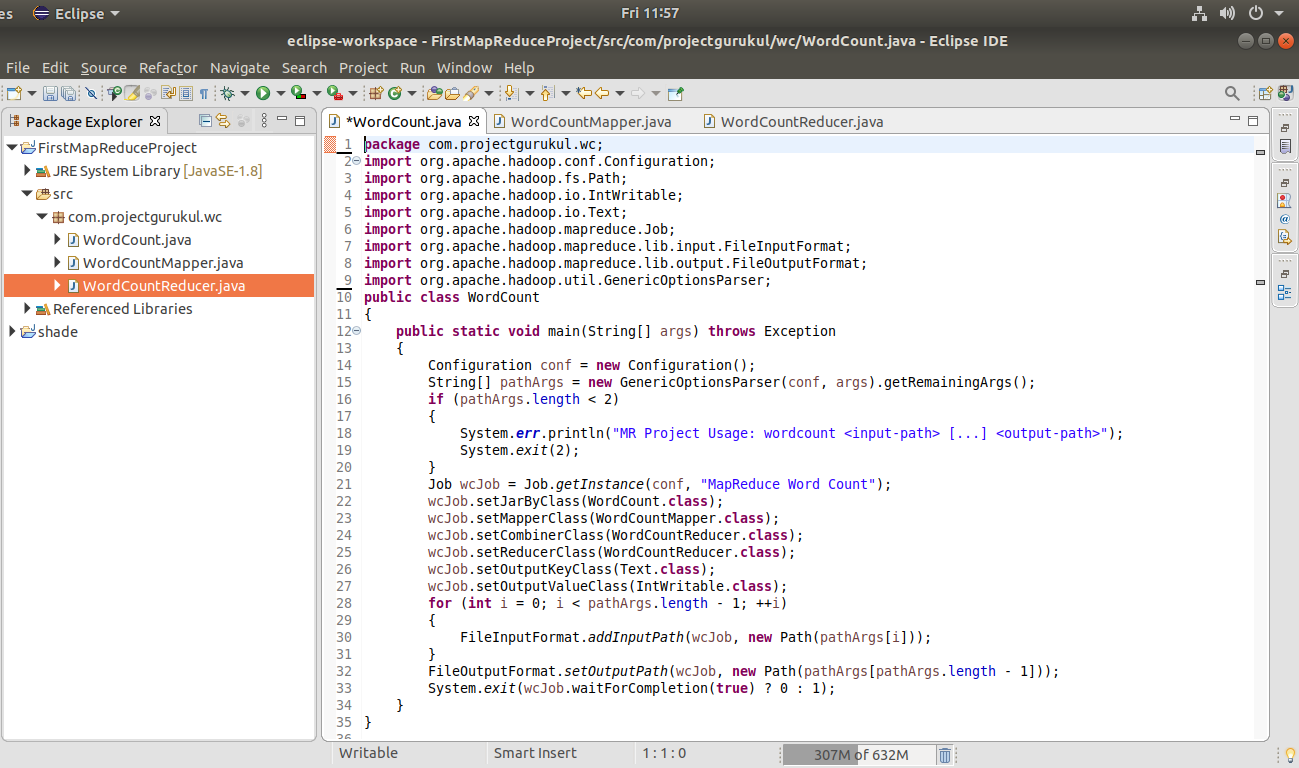
Press Ctrl+S to save the Code.
Step 11. Creating the Jar File of the Project
Before running created Hadoop MapReduce word count application, we have to create a jar file.
To do so Right-click on project name >> Export.
Select the JAR file option. Click Next.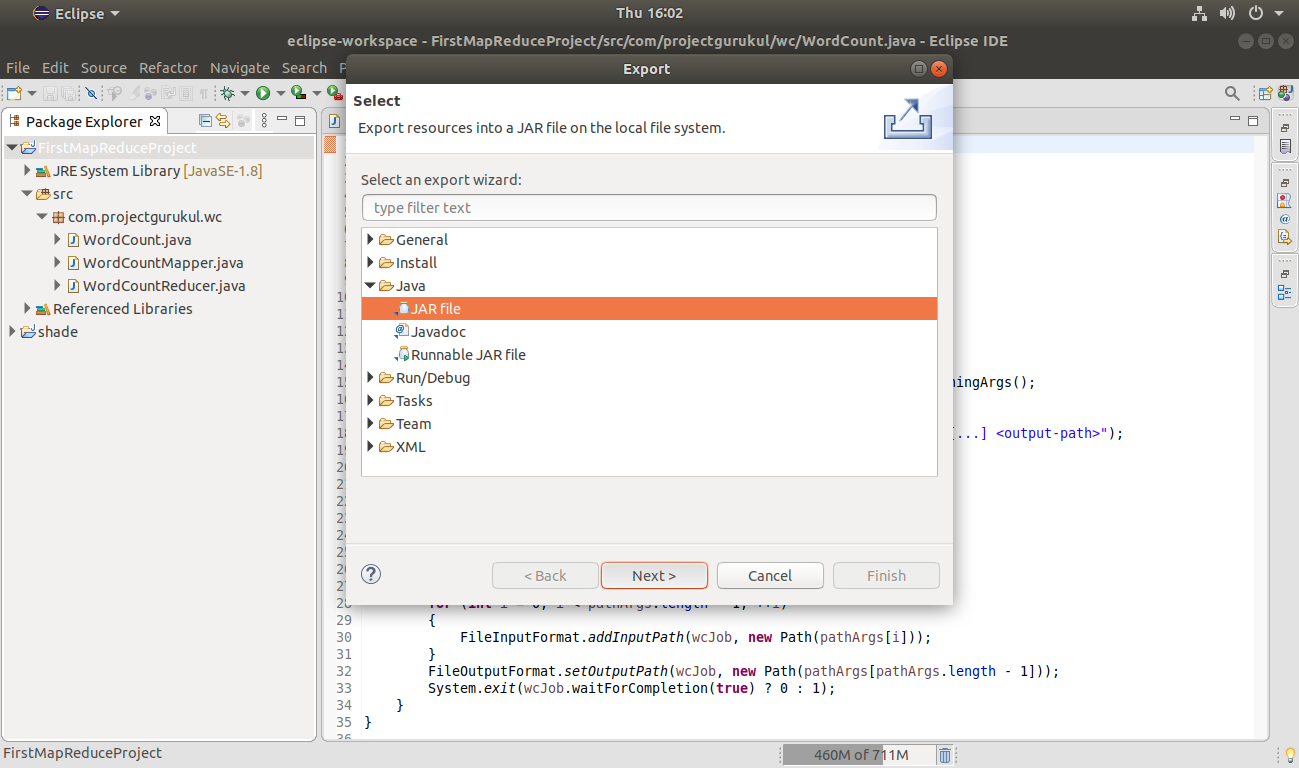
Provide the Jar file name: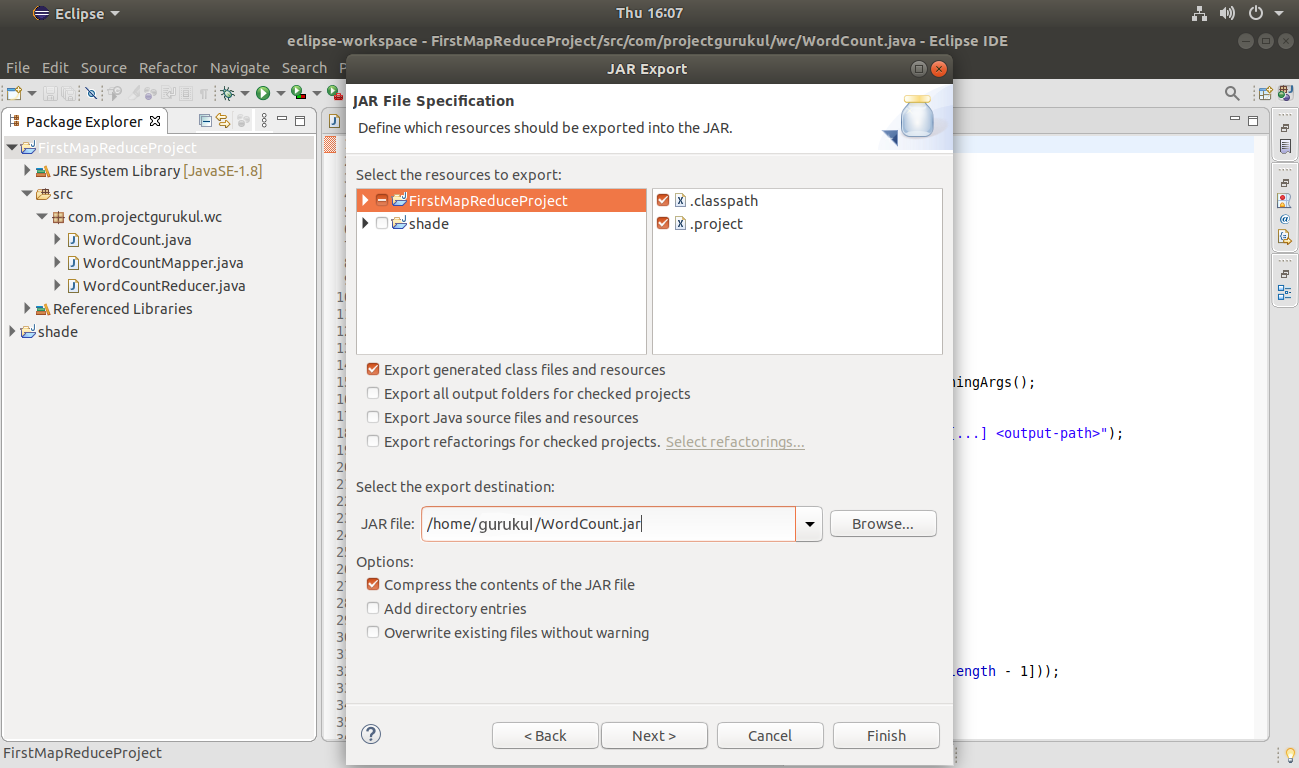
Click Next.
Click Next.
Now select the class of the application entry point.
Here in this Hadoop MapReduce Project article, the class for the application entry point is the WordCount class.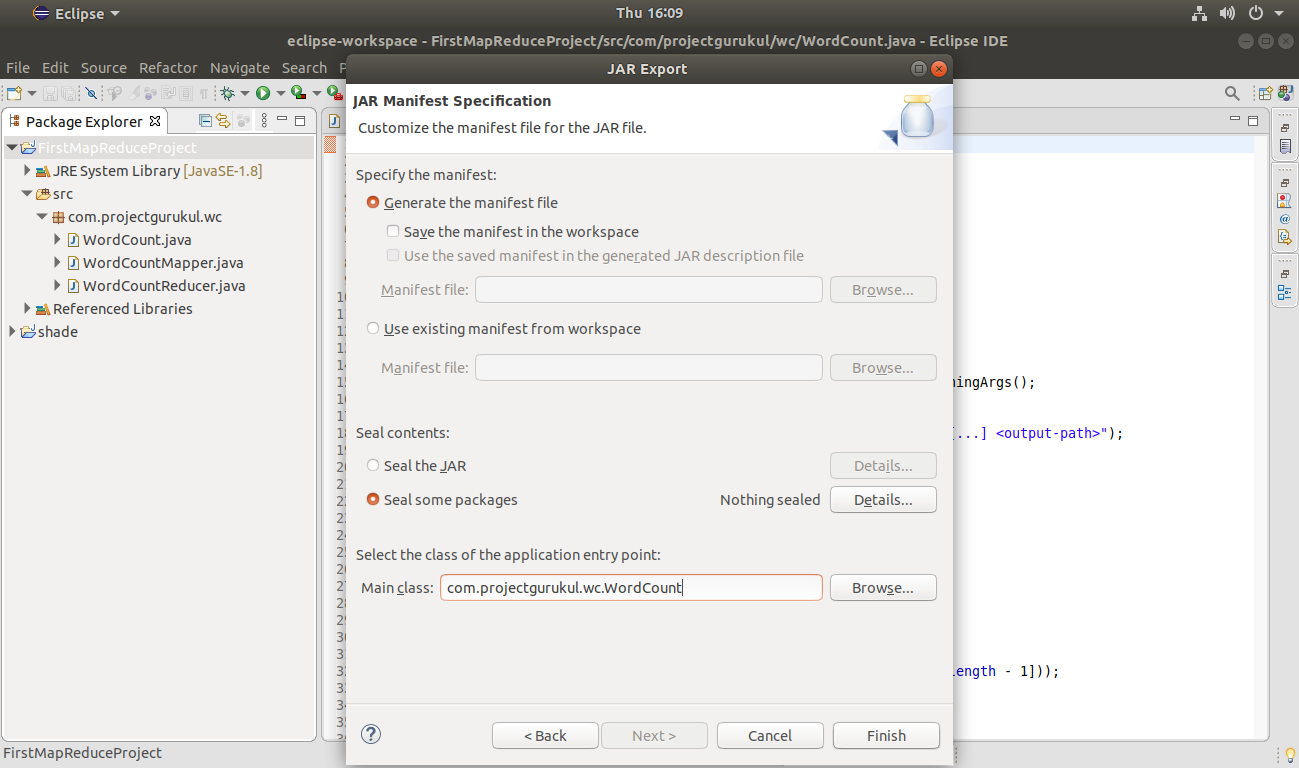
Click Finish.
Step 12. Execute the Hadoop MapReduce word count application using the below execution command.
hadoop jar <project jar file path> <input file path> <output directory>
hadoop jar /home/gurukul/WordCount.jar /wc_input /wc_output
Here in this command,
- <project jar file path> is the path of the jar file of the project created above.
- <input file path> is the file in HDFS, which is input to the Hadoop MapReduce Word Count Project.
- <output directory> is the directory where the output of the Hadoop MapReduce WordCount program is going to be stored.
 This will start the execution of MapReduce job
This will start the execution of MapReduce job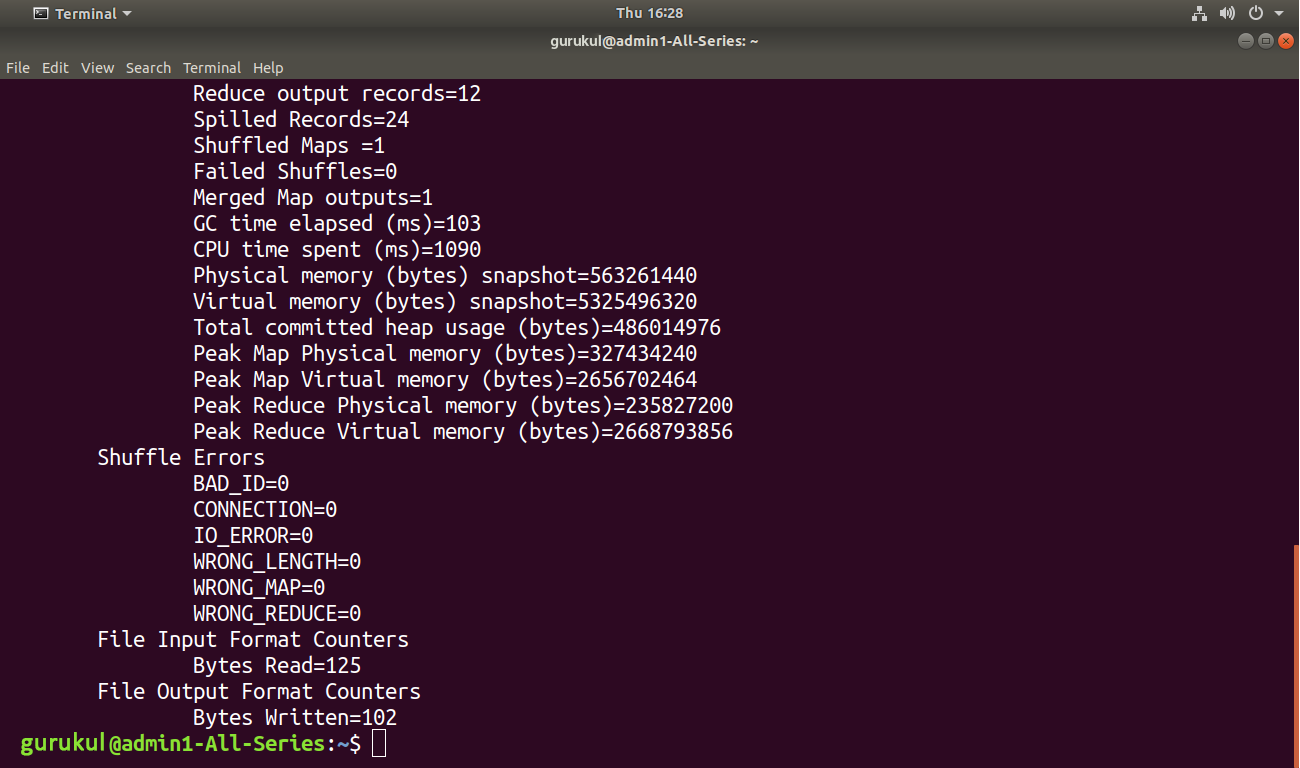
Now we have run the Map Reduce job successfully. Let us now check the result.
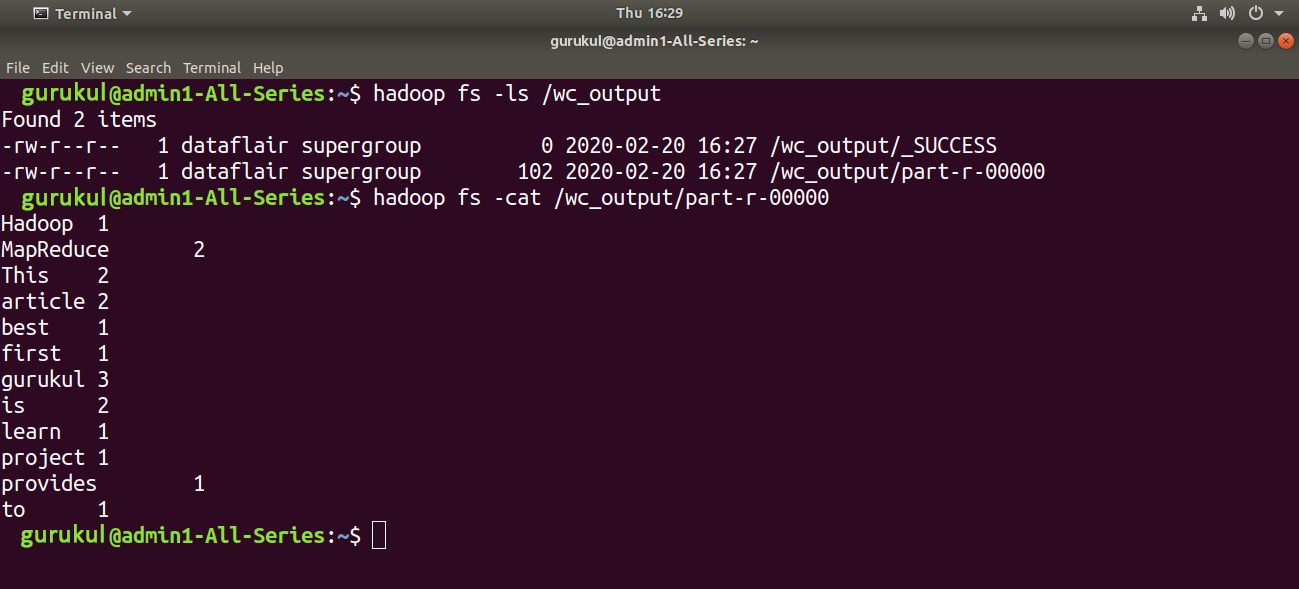
Step 13. Browse the Hadoop MapReduce Word Count Project Output.
The output directory of the Project in HDFS contains two files: _SUCCESS and part-r-00000
The output is present in the /part-r-00000 file.
You can browse the result using the below command.
hadoop fs -cat <output directory/part-r-00000>
hadoop fs -cat /wc_output/part-r-00000
Summary
We have Successfully created the Hadoop MapReduce Project in Java with Eclipse and executed the MapReduce job on Ubuntu. If you have any doubts in any of the steps, ask in the comment section.
Exception in thread “main” java.lang.UnsupportedClassVersionError: com/projectgurukul/wc/WordCount has been compiled by a more recent version of the Java Runtime (class file version 61.0), this version of the Java Runtime only recognizes class file versions up to 52.0
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:756)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:473)
at java.net.URLClassLoader.access$100(URLClassLoader.java:74)
at java.net.URLClassLoader$1.run(URLClassLoader.java:369)
at java.net.URLClassLoader$1.run(URLClassLoader.java:363)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:362)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hadoop.util.RunJar.run(RunJar.java:316)
at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
same
Sir how to find the file path of the jar file?
If you’re using windows find the file and right click to select properties and look at the file path. Mine was on my desktop.
Very Superb.. Good job.