Convert PDF to AudioBook and Audio Speech to PDF using Python
FREE Online Courses: Dive into Knowledge for Free. Learn More!
In this Python project, we will build a GUI-based PDF to Audio and Audio to PDF converter using the Tkinter, OS, path, pyttsx3, SpeechRecognition, PyPDF4, and Pydub libraries and the messagebox module of the Tkinter library. It is an intermediate level project, and you will be able to apply the concepts you have learnt in real life. Let’s get started!?
About PDF to Audio converters:
PDF to Audio Converters are able to convert the PDF text to speech.
In this project, we will convert any one page of the PDF to speech that you will be able to hear almost instantaneously.
About Audio to PDF converters:
Audio to PDF converters convert an audio file to text, which is added to an already-existing PDF or a non-existing PDF.
In this project, we will ask you for an audio file that we will transcribe to text that will be added to a PDF file. This will be speech to text conversion.
About the project:
The objective of this project is to create a GUI based PDF text to Audio and Audio to PDF converter. To build this, you will need intermediate understanding of Tkinter, OS, path, SpeechRecognition and PyPDF4 libraries and basic understanding of the Pydub and pyttsx3 libraries and messagebox module.
Project Prerequisites:
To build this project, we will need the following libraries:
1. Tkinter – To make the GUI
2. os.path – To get the file name (with extension)
3. PyPDF4.pdf:
a. PdfFileReader – To read text from the PDF.
b. PdfFileWriter – To add a new page in the PDF where text can be added.
4. pyttsx3 – To speak the text using the machine’s speakers in an automated voice.
5. SpeechRecognition – To transcribe the speech in the audio file.
6. path:
a. Path – To convert a string to the path to a file.
7. pydub – To manipulate an audio file.
Only the Tkinter and OS libraries come pre-installed with Python, so you will need to run the following commands in your terminal to install them:
python -m pip install path pydub python -m pip install PyPDF4 python -m pip install pyttsx3 SpeechRecognition
Or, you run this one command:
python -m pip install path pydub PyPDF4 pyttsx3 SpeechRecognition
Download PDF to AudioBook Converter Project
Please download the source code of python pdf to audio book and audio speech to pdf converter Project: Python PDF to AudioBook Converter Project Code
Project File Structure:
Here are the steps you will need to execute to build this project:
1. Importing all the necessary libraries and modules
2. Creating the Window class and the constructor method
3. Creating the conversion methods
4. Creating the GUI windows for the conversions as methods of the class
Let’s take a closer look at these steps:
1. Importing all the necessary libraries and modules:
from tkinter import * import tkinter.messagebox as mb from path import Path from PyPDF4.pdf import PdfFileReader as PDFreader, PdfFileWriter as PDFwriter import pyttsx3 from speech_recognition import Recognizer, AudioFile from pydub import AudioSegment import os
2. Creating the Window class and the constructor method:
class Window(Tk):
def __init__(self):
super(Window, self).__init__()
self.title("ProjectGurukul PDF to Audio and Audio to PDF converter")
self.geometry('400x250')
self.resizable(0, 0)
self.config(bg='Burlywood')
Label(self, text='ProjectGurukul PDF to Audio and Audio to PDF converter', wraplength=400,
bg='Burlywood', font=("Comic Sans MS", 15)).place(x=0, y=0)
Button(self, text="Convert PDF to Audio", font=("Comic Sans MS", 15), bg='Tomato',
command=self.pdf_to_audio, width=25).place(x=40, y=80)
Button(self, text="Convert Audio to PDF", font=("Comic Sans MS", 15), bg='Tomato',
command=self.audio_to_pdf, width=25).place(x=40, y=150)
Explanation:
- In this step, we will initially create the constructor method of our Window class where we will define our main window, which will navigate to our conversion windows.
- In our main window, there will only be a header label and two buttons, which will navigate to our conversion.
3. Creating the GUI windows for the conversions as methods of the class:
def pdf_to_audio(self):
pta = Toplevel(self)
pta.title('Convert PDF to Audio')
pta.geometry('500x300')
pta.resizable(0, 0)
pta.config(bg='Chocolate')
Label(pta, text='Convert PDF to Audio', font=('Comic Sans MS', 15), bg='Chocolate').place(relx=0.3, y=0)
Label(pta, text='Enter the PDF file location (with extension): ', bg='Chocolate', font=("Verdana", 11)).place(x=10, y=60)
filename = Entry(pta, width=32, font=('Verdana', 11))
filename.place(x=10, y=90)
Label(pta, text='Enter the page to read from the PDF (only one can be read): ', bg='Chocolate', font=("Verdana", 11)).place(x=10, y=140)
page = Entry(pta, width=15, font=('Verdana', 11))
page.place(x=10, y=170)
Button(pta, text='Speak the text', font=('Gill Sans MT', 12), bg='Snow', width=20,
command=lambda: self.speak_text(filename.get(), page.get())).place(x=150, y=240)
def audio_to_pdf(self):
atp = Toplevel(self)
atp.title('Convert Audio to PDF')
atp.geometry('675x300')
atp.resizable(0, 0)
atp.config(bg='FireBrick')
Label(atp, text='Convert Audio to PDF', font=("Comic Sans MS", 15), bg='FireBrick').place(relx=0.36, y=0)
Label(atp, text='Enter the Audio File location that you want to read [in .wav or .mp3 extensions only]:',
bg='FireBrick', font=('Verdana', 11)).place(x=20, y=60)
audiofile = Entry(atp, width=58, font=('Verdana', 11))
audiofile.place(x=20, y=90)
Label(atp, text='Enter the PDF File location that you want to save the text in (with extension):', bg='FireBrick' ,font=('Verdana', 11)).place(x=20, y=140)
pdffile = Entry(atp, width=58, font=('Verdana', 11))
pdffile.place(x=20, y=170)
Button(atp, text='Create PDF', bg='Snow', font=('Gill Sans MT', 12), width=20,
command=lambda: self.speech_recognition(audiofile.get(), pdffile.get())).place(x=247, y=230)
Explanation:
- Next, we will create the conversion windows, the GUI windows where our user will enter the initial information.
- In the pdf_to_audio() method, where we will convert text from a page of a PDF file to speech, our GUI window will be a TopLevel widget, with two entry fields: the first one asking for the path to the PDF file, and the second one asking for the page number from which the text should be read.
The button in the window will take these two entry fields as arguments and run it through the speak_text() function, which we will learn to create in the next step. - In the audio_to_pdf() method, where we will convert the speech of an audio file to text in a PDF file, we will have two entry fields where the first one will ask for the path to an audio file that should only be in .wav and .mp3 formats and the second one will take the path to a PDF file.
The button in this window will take the two paths as arguments and run them through the speech_recognition() function where the audio file will be transcribed.
4. Creating the conversion methods:
@staticmethod
def speak_text(filename, page):
if not filename or not page:
mb.showerror('Missing field!', 'Please check your responses, because one of the fields is missing')
return
reader = PDFreader(filename)
engine = pyttsx3.init()
with Path(filename).open('rb'):
page_to_read = reader.getPage(int(page)-1)
text = page_to_read.extractText()
engine.say(text)
engine.runAndWait()
@staticmethod
def write_text(filename, text):
writer = PDFwriter()
writer.addBlankPage(72, 72)
pdf_path = Path(filename)
with pdf_path.open('ab') as output_file:
writer.write(output_file)
output_file.write(text)
def speech_recognition(self, audio, pdf):
if not audio or not pdf:
mb.showerror('Missing field!', 'Please check your responses, because one of the fields is missing')
return
audio_file_name = os.path.basename(audio).split('.')[0]
audio_file_extension = os.path.basename(audio).split('.')[1]
if audio_file_extension != 'wav' and audio_file_extension != 'mp3':
mb.showerror('Error!', 'The format of the audio file should only be either "wav" and "mp3"!')
if audio_file_extension == 'mp3':
audio_file = AudioSegment.from_file(Path(audio), format='mp3')
audio_file.export(f'transcript.wav', format='wav')
source_file = 'transcript.wav'
r = Recognizer()
with AudioFile(source_file) as source:
r.pause_threshold = 5
speech = r.record(source)
text = r.recognize_google(speech)
self.write_text(pdf, text)
Explanation:
- @staticmethod is used to convert a method indented under a Class definition to an autonomous function that is not bound to the scope of the Class.
- We will take 2 arguments in the speak_text() method, which will be our path to the PDF file and the page number that the user wants the computer to read.
- At the start, we will check if the file path and the page number arguments are not empty. If they are, we will stop the function from further functioning.
- Then, we will initiate the pyttsx3 engine.
- After that, we will open our PDF file in the read mode, where we will get the page number the user asked for, extract the text from that page and then use the pyttsx3 engine to read the text.
- To convert audio into text in a PDF file, we will use two functions: speech_recognition() and write_text(). We will first run the speech recognition function which will p3 formats, and convert .mp3 files to .wav files and then transcribe the said file.recognise the audio file after checking that the audio file is in the .wav or .m
After that, we will provide the write_text() function with the path to the PDF file and the text that has been transcribed. In this function, we will add a new page to the PDF using the PdfFileWriter object after we open the file in append mode. In the new page, the transcribed text will be written.
The final code:
from tkinter import *
import tkinter.messagebox as mb
from path import Path
from PyPDF4.pdf import PdfFileReader as PDFreader, PdfFileWriter as PDFwriter
import pyttsx3
from speech_recognition import Recognizer, AudioFile
from pydub import AudioSegment
import os
# Initializing the GUI window
class Window(Tk):
def __init__(self):
super(Window, self).__init__()
self.title("ProjectGurukul PDF to Audio and Audio to PDF converter")
self.geometry('400x250')
self.resizable(0, 0)
self.config(bg='Burlywood')
Label(self, text='ProjectGurukul PDF to Audio and Audio to PDF converter', wraplength=400,
bg='Burlywood', font=("Comic Sans MS", 15)).place(x=0, y=0)
Button(self, text="Convert PDF to Audio", font=("Comic Sans MS", 15), bg='Tomato',
command=self.pdf_to_audio, width=25).place(x=40, y=80)
Button(self, text="Convert Audio to PDF", font=("Comic Sans MS", 15), bg='Tomato',
command=self.audio_to_pdf, width=25).place(x=40, y=150)
def pdf_to_audio(self):
pta = Toplevel(self)
pta.title('Convert PDF to Audio')
pta.geometry('500x300')
pta.resizable(0, 0)
pta.config(bg='Chocolate')
Label(pta, text='Convert PDF to Audio', font=('Comic Sans MS', 15), bg='Chocolate').place(relx=0.3, y=0)
Label(pta, text='Enter the PDF file location (with extension): ', bg='Chocolate', font=("Verdana", 11)).place(x=10, y=60)
filename = Entry(pta, width=32, font=('Verdana', 11))
filename.place(x=10, y=90)
Label(pta, text='Enter the page to read from the PDF (only one can be read): ', bg='Chocolate',
font=("Verdana", 11)).place(x=10, y=140)
page = Entry(pta, width=15, font=('Verdana', 11))
page.place(x=10, y=170)
Button(pta, text='Speak the text', font=('Gill Sans MT', 12), bg='Snow', width=20,
command=lambda: self.speak_text(filename.get(), page.get())).place(x=150, y=240)
def audio_to_pdf(self):
atp = Toplevel(self)
atp.title('Convert Audio to PDF')
atp.geometry('675x300')
atp.resizable(0, 0)
atp.config(bg='FireBrick')
Label(atp, text='Convert Audio to PDF', font=("Comic Sans MS", 15), bg='FireBrick').place(relx=0.36, y=0)
Label(atp, text='Enter the Audio File location that you want to read [in .wav or .mp3 extensions only]:',
bg='FireBrick', font=('Verdana', 11)).place(x=20, y=60)
audiofile = Entry(atp, width=58, font=('Verdana', 11))
audiofile.place(x=20, y=90)
Label(atp, text='Enter the PDF File location that you want to save the text in (with extension):', bg='FireBrick' ,font=('Verdana', 11)).place(x=20, y=140)
pdffile = Entry(atp, width=58, font=('Verdana', 11))
pdffile.place(x=20, y=170)
Button(atp, text='Create PDF', bg='Snow', font=('Gill Sans MT', 12), width=20,
command=lambda: self.speech_recognition(audiofile.get(), pdffile.get())).place(x=247, y=230)
@staticmethod
def speak_text(filename, page):
if not filename or not page:
mb.showerror('Missing field!', 'Please check your responses, because one of the fields is missing')
return
reader = PDFreader(filename)
engine = pyttsx3.init()
with Path(filename).open('rb'):
page_to_read = reader.getPage(int(page)-1)
text = page_to_read.extractText()
engine.say(text)
engine.runAndWait()
@staticmethod
def write_text(filename, text):
writer = PDFwriter()
writer.addBlankPage(72, 72)
pdf_path = Path(filename)
with pdf_path.open('ab') as output_file:
writer.write(output_file)
output_file.write(text)
def speech_recognition(self, audio, pdf):
if not audio or not pdf:
mb.showerror('Missing field!', 'Please check your responses, because one of the fields is missing')
return
audio_file_name = os.path.basename(audio).split('.')[0]
audio_file_extension = os.path.basename(audio).split('.')[1]
if audio_file_extension != 'wav' and audio_file_extension != 'mp3':
mb.showerror('Error!', 'The format of the audio file should only be either "wav" and "mp3"!')
if audio_file_extension == 'mp3':
audio_file = AudioSegment.from_file(Path(audio), format='mp3')
audio_file.export(f'{audio_file_name}.wav', format='wav')
source_file = f'{audio_file_name}.wav'
r = Recognizer()
with AudioFile(source_file) as source:
r.pause_threshold = 5
speech = r.record(source)
text = r.recognize_google(speech)
self.write_text(pdf, text)
# Finalizing the GUI window
app = Window()
app.update()
app.mainloop()
Python PDF to Audio Speech Converter Output
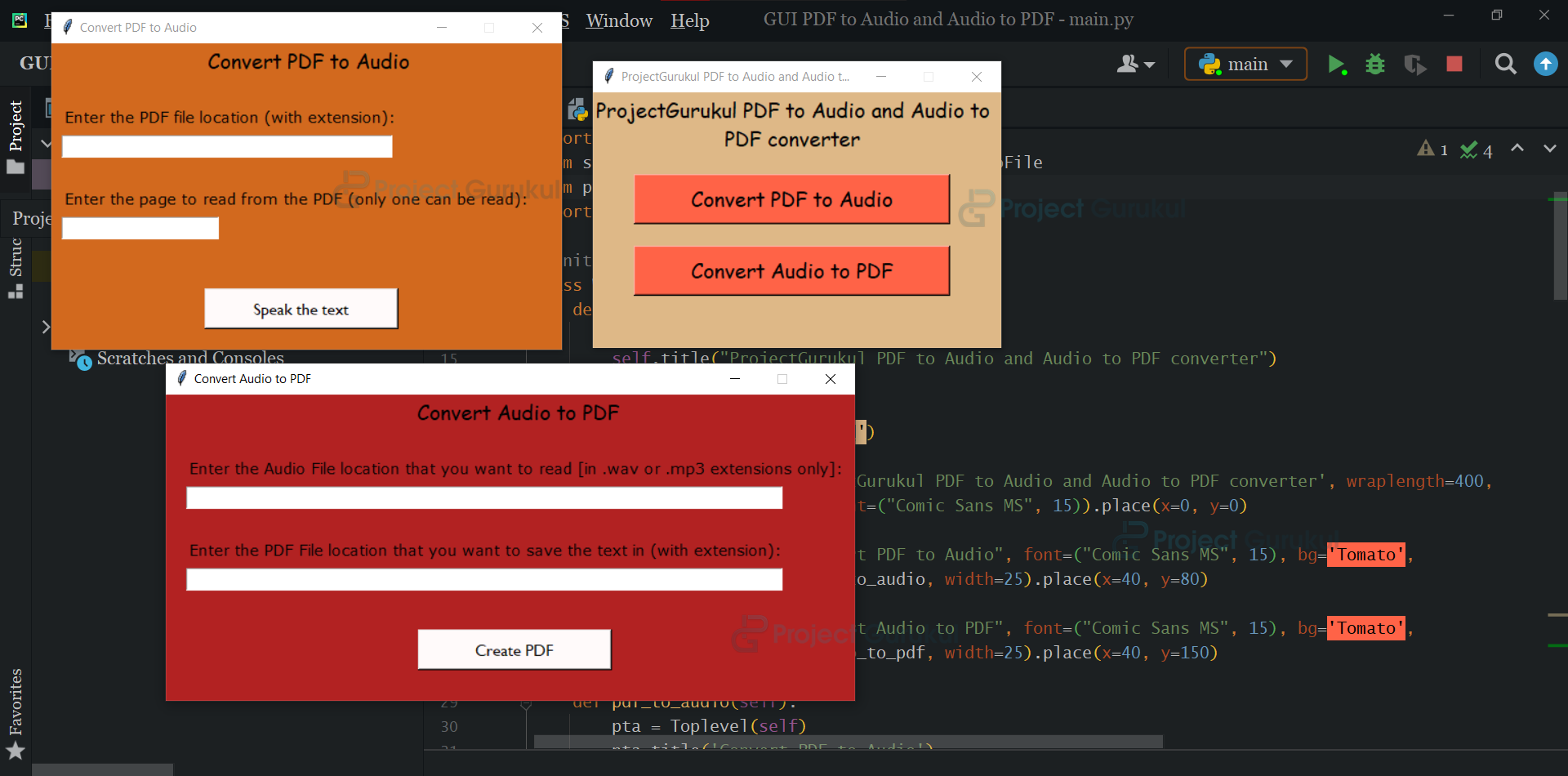
Summary:
Congratulations! You have now created your own PDF to Audio and Audio to PDF Converter using the Tkinter, OS, path, pyttsx3, SpeechRecognition, Pydub and PyPDF4 libraries and the messagebox module of the Tkinter library.
You can use this project to transcribe some audio files or convert the text in PDFs to speech.
However, this project has a lot of capability to expand, and you can do so with the power of programming, so continue improving it.
Have fun coding!?
Exception in Tkinter callback
Traceback (most recent call last):
File “C:\Users\satis\anaconda3\lib\tkinter\__init__.py”, line 1892, in __call__
return self.func(*args)
File “C:\Users\satis\AppData\Local\Temp/ipykernel_21264/2627334016.py”, line 48, in
command=lambda: self.speak_text(filename.get(), page.get())).place(x=150, y=240)
File “C:\Users\satis\AppData\Local\Temp/ipykernel_21264/2627334016.py”, line 77, in speak_text
reader = PDFreader(filename)
File “C:\Users\satis\anaconda3\lib\site-packages\PyPDF4\pdf.py”, line 1148, in __init__
self.read(stream)
File “C:\Users\satis\anaconda3\lib\site-packages\PyPDF4\pdf.py”, line 1762, in read
line = self.readNextEndLine(stream)
File “C:\Users\satis\anaconda3\lib\site-packages\PyPDF4\pdf.py”, line 2002, in readNextEndLine
raise utils.PdfReadError(“Could not read malformed PDF file”)
PyPDF4.utils.PdfReadError: Could not read malformed PDF file