Automatic Music Generation – Generate Music using LSTM
FREE Online Courses: Click for Success, Learn for Free - Start Now!
With this Machine Learning Project, we will be building an automatic music generation. Automatic music generation is a system that will be given some initial music notes and the algorithm is trained in a way that it will predict what the next note is. Then we will combine this note with the initial notes and will again pass it to the system and it will predict the next node for us. This way we are going to get new notes every time and we will combine all these notes to generate nice music.
So, let’s start with the project.
Music Generation
Humans have created music for a very long time. The Seikilos Epitaph from the first or second century AD is the first full musical composition, according to the book “Ancient Greek Music: A Survey”.
These days, the music instrument’s digital interface (midi), which transmits data like pitch and duration, is the protocol used by electronic instruments to connect to a computer. Without having an actual orchestra, composers can create orchestras using midi. Each instrument in the orchestra could be produced via MIDI. The digital audio workstation (DAW) is the industry standard for recording, editing, mastering, and mixing in modern audio production. You can independently play each channel to the electronic instruments or synthesizers linked to this DAW. Several algorithmic composition approaches include the Markov model, generative grammars, transition networks, artificial neural networks, etc.
In this machine learning project, we will be building a system that will generate music by itself and the algorithm we will use is LSTM.
RNN
RNNs belong to the feed-forward family of neural networks. They differ from other feed-forward networks in that they may send data over time increments. An RNN evaluates a series of inputs xt and outputs yt that are indexed by a parameter t that denotes the time rather than a single input x and a single output y.
To compute the next value for a hidden layer (ht + 1), the outputs from a hidden layer (ht + 1) essentially reenter themselves as an additional input. As a result, the network may benefit from both recent and historical data. It can also pick up knowledge from series, such as temporal ones. The following image shown below describes how RNN can be viewed as many copies of a Feed-Forward ANN working together in a chain.
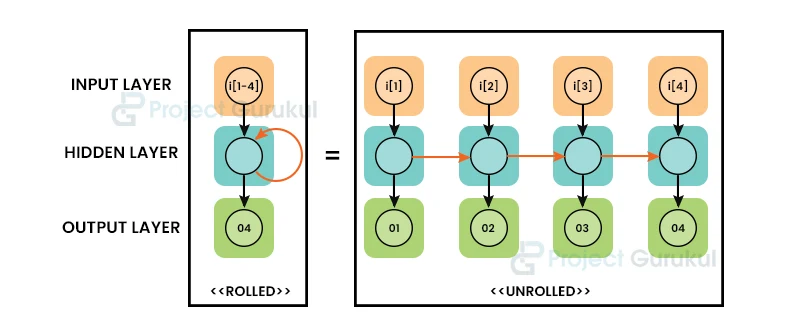
Recurrent networks have a training issue since backpropagation across time made estimating gradients (BPTT) difficult. The vanishing gradient problem, which is caused by over-minimizing or amplifying effects, is represented via backpropagation through time. The BPTT algorithm calculates the gradient of each step in an unrolled graph using a back-propagation technique.
The Model Architecture
In this machine learning project, we will train midi data using the Long Short-Term Memory (LSTM) approach and subjectively assess music output. A recurrent neural network (RNN) can be used as an input for a properly encoded midi file. However, learning how to switch between musical forms is difficult.
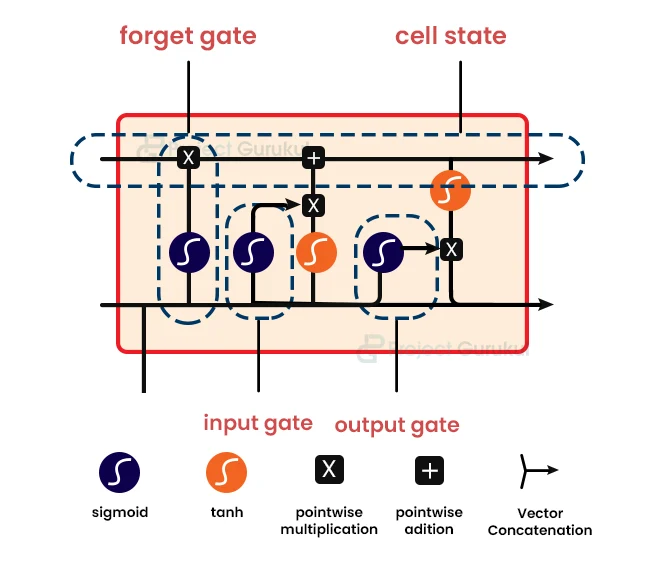
The LSTM unit was proposed by Hochreiter and Schmidhuber. Since then, LSTM has seen a few changes. The diagram below shows the LSTM block schematic. It has block input, a single cell, an output activation function, peephole connections, three gates (input, forget, and output), and block output. The input of the block, as well as all of the gates, are recurrently connected to the block’s output.
We’re going to use Midi for training. A midi file contains 128 pitch notes. Only 88 patch notes are played on the piano from notes 21 to 108. (A0–C8). The pitch notes of the piano are represented by the columns of a vector array of size 1 * 88. One vector array corresponds to a quartet of fourteenth notes in the quaver notes time signature. Midi Encoding produces midi matrixes. We will provide the Midi Matrix to the model, which will then be trained by LSTM independently to obtain the results.
Project Prerequisites
The required modules for this project are :
- Pandas – pip install pandas
- Numpy- pip install numpy
- Music21 – pip install music21
- Sklearn – pip install sklearn
- Tensorflow – pip install tensorflow
These will be the libraries we will be using in this project. Music21 is a library that gives us some functions to work with music files.
Automatic Music Generation Project
The dataset contains music notes file with extension .mid files. You can download automatic music generation machine learning project code and dataset from the following link: Automatic Music Generation Project
Steps to Implement Automatic Music Generation Project
1. Import all the modules that we will require in the project.
import pickle #importing the libraries import numpy#importing the numpy library from music21 import instrument, note, stream, chord #importing the music library from keras.models import Sequential#importing the sequential library from keras.layers import Dense #imoprpting the dense library from keras.layers import Dropout#importing the Dropout library from keras.layers import LSTM#importing the LSTM library from keras.layers import BatchNormalization as BatchNorm#importing the batch normalization function from keras.layers import Activation#importing the activation function
2. This is a function where we generate the music. This is the main function where we call other functions that will help in the process of music creation.
def generate(): #here we are defining a function
with open('data/notes', 'rb') as filepath:#opening a file
notes = pickle.load(filepath)#loading the file using pickle
pitchnames = sorted(set(item for item in notes))#using the sorted function to sort the items in file
n_vocab = len(set(notes))#counting the length of the notes.
network_input, normalized_input = prepare_sequences(notes, pitchnames, n_vocab)#here we are preparing the sequence for the notes.
model = create_network(normalized_input, n_vocab)#here we are creating the networks
prediction_output = generate_notes(model, network_input, pitchnames, n_vocab)#here we are generating the notes using the model.
create_midi(prediction_output)#here we are calling the create_midi function
3. This is the function where we are reading the music file and converting the music and notes into sequences. These sequences will be used as an input data to our network that we will create.
def prep_seq(not, ptchname, n_vocab):#defining the function
notetoint = dict((no, number) for number, no in enumerate(ptchname))#creating the dictionary
seq_len = 100
net_input = []
out = []
for i in range(0, len(not) - seq_len , 1):
seq_in = not[i:i + seq_len ]
seq_out = not[i + seq_len ]
net_input.append([notetoint[char] for char in seq_in])
out.append(notetoint[seq_out])
n_patterns = len(net_input)
norm_input = numpy.reshape(net_input, (n_patterns, seq_len , 1))
# normalize input
norm_input = norm_input / float(n_vocab)
return (net_input, norm_input)
4. Here is just a simple code for creating an LSTM model that is a function that will take input data that we have created in the previous step. This is not a complicated code. We have just used the inbuilt functions in TensorFlow to create the network.
def network_create(net_in, voc):
m = Sequential()#creating the model
m.add(LSTM(
512,
input_shape=(net_in.shape[1], net_in.shape[2]),
recurrent_dropout=0.3,
return_sequences=True
))#adding layers and features to our model.
m.add(LSTM(512, return_sequences=True, recurrent_dropout=0.3,))#adding LSTM Layer
m.add(LSTM(512))#adding LSTM Layer
m.add(BatchNorm())#adding batch norm layer
m.add(Dropout(0.3))#adding dropout layer
m.add(Dense(256))#adding dense layer
m.add(Activation('relu'))#adding activation layer
m.add(BatchNorm())#adding batch norm layer
m.add(Dropout(0.3))#adding dropout layer
m.add(Dense(voc))#adding dense layer
m.add(Activation('softmax'))#adding activation softmax function
m.compile(loss='categorical_crossentropy', optimizer='rmsprop')#compiling the model
m.load_weights('weights.hdf5')#loading the weights
return m
5. Here in this section of the code, we have created a function that will finally generate the music for us. We have given it a value of 500 which means it will predict 500 notes for us. Finally, we are storing all these into a list called prediction output variable.
def note_generate(m, net_in, ptchname, voc):
s= numpy.random.randint(0, len(net_in)-1)
inttonote = dict((num, n) for num, n in enumerate(ptchname))
pat = net_in[s]
pred_out = []
for notin in range(500):
pred_in = numpy.reshape(pat, (1, len(pat), 1))
pred_in = pred_in / float(voc)
pred = m.predict(pred_in, verbose=0)
i = numpy.argmax(pred)
res = inttonote[i]
pred_out.append(res)
pat.append(i)
pat = pat[1:len(pat)]
return pred_out
6. This is the portion of the code where we are creating our midi file. The prediction of the notes that we have created in the previous step will be used as an input to this function. We have run a for loop to check where the particular pattern in the list is either a note or a chord. Based on this, we are creating different objects for chords and notes.
def midi_create(pred_out):
out_not = []
for pat in pred_out:
if ('.' in pat) or pat.isdigit():
noteinchord = pat.split('.')
not = []
for cur_note in noteinchord :
newnote = not.Note(int(current_note))
newnote.storedInstrument = instrument.Piano()
not.append(newnote)
newchord = chord.Chord(notes)
newchord.offset = 10
out_not.append(newchord)
else:
newnote = not.Note(pattern)
newnote.offset = 10
newnote.storedInstrument = instrument.Piano()
outnot.append(newnote)
midistream = stream.Stream(out_not)
midistream.write('midifile', fp='output.mid')
7. This is the main file where we are calling our generate function.
if __name__ == '__main__':#calling the function
generate()#calling the generate function
Summary
In this Machine Learning project, we learned how to build an automatic music generation system. This music generation system can be further converted into apps. Or you can train it on more number of songs if you have that much GPU power in your system and you can obtain much more pleasing music from it.